|
Abstract Booklet E-Book Format Contents Causative Constructions in Magahi Alok, Deepak Ananda, M. G. Lalith Crosslinguistic Semantic and
Translation Priming in Normal Bilingual Individuals across Gender Arya, Pravesh, Akanksha Gupta,
Brajesh Priyadarshi Attar, Mahan & S.S.Chopra Phonological, Grammatical and Lexical
Interference in Adult Multilingual Subjects Avanthi. N & Abhishek. B.P Baraik, Sunil Barodawala, Asma I. & T. Sree
Ganesh Naming Deficits in Bilingual Aphasia Batra, Ridhima & Pallavi Malik
& Shyamala K.C Voicing patterns in Indian English Bhattacharya, Pratibha Resultative and Stative in Bangla: How
different? Bhattacharya, Shiladitya Cardoso, Hugo Canelas Revised Receptive Expressive Emergent
Language Scales for Kannada Speaking Children Deepa M.S., Madhu K, Harshan K
& Suhas Devika.M.R, Navitha U & Dr.
Sapna N. ELDP Data Collection: Some Baram Experiences Dhakal, Dubi Nanda, TR Kansakar, YP Yadava, KP Chalise, BR Prasain, Krishna Paudel Jadhav, Arvind & Nick Ward Lexical Organization in Malayalam-English
Bilinguals Joy, Sweety, Meera Priya.C.S,
Aiswarya Anand & Jayashree Shanbal Temporality in Bengali: A Syntacto-Semantic
Framework Karmakar, Samir Gilchrist's 'A Grammar of Hindoostanee
Language': Some Colonial and Contemporary Imprints Kumar, Santosh The Biolinguistic Diversity Index of
India Kumar, Ritesh Kumar, Shailendra & Neha
Vashistha Gitanjali�: A Study in Lyrical Patterns (Syntax,
Diction & Rhythm) Kusum Case marking in Asamiya in comparison with Bangla Lahiri, Bornini The Semantics of Classifiers in some Indian
Languages Lahiri, Bornini, Ritesh Kumar,
Sudhanshu Shekhar & Atanu Saha Word Retrieval Abilities in Bilingual
Geriatrics Maitreyee, Ramya & Ridhima
Batra Implementation of Transfer Grammar in
Telugu Hindi Machine Translation System Mala, Christopher Automatic
Extraction and Incorporation of Purpose Data into Purposenet Mayee, P. Kiran Developing a Morphological Analyzer for
Kashmiri Mehdi, Nazima, Aadil A. Laway
& Feroz Ahmad Lone Second Language (L2) Vocabulary Acquisition in
Icelandic Contexts Misirili, Nilufer Pronominal Binding in Hindi-Urdu vis-�-vis
Bangla Mukherjee, Aparna Naidu, Y. Viswanatha Naresh D. Nash, Joshua Reflexivity and Causation: A Study of the
Vector ghe (TAKE) in Marathi Ozarkar, Renuka Pande, Hemlata Cross Language Variants in Linguistic
Deficits in Dementia of Alzheimer�s Type (DAT) Individuals Ravi, Sunil Kumar Positional Faithfulness for Weak
Positions Sanyal, Paroma Main Verb and Light Verb in Bangla: Only Apparent
Synonymy? Saurov, Syed Role of Working Memory in Typically Developing
Children�s Complex Sentence Comprehension Shwetha M.P, Deepthi M., Trupthi
T.& Deepa M.S. Beyond Honorificity: Analysis of Hindi
jii Thakur, Gayetri Fastmapping Skills in the Developing Lexicon in
Kannada Speaking Children Trupthi T., Deepthi M., Shwetha
M.P., & Deepa M.S. & Nikhil Mathur A Knowledge-Rich Computational
Analysis of Marathi Derived Forms Vaidya, Ashwini Communication through Secret Language:
A Case Study Based on Parayas� Secret Language Vamanan, Dileep Vijay, Dharurkar Chinmay Book of Abstracts Causative Constructions in Magahi
Deepak
Alok Deptt. of Linguistics, BHU, Varanasi E.
Mail: deepak113alok@yahoo.co.in Causative constructions play a
significant role in different areas of the grammar of a language. Some languages
exhibit morphological causativization whereas some languages undergo complex
syntactic processes to realize causative constructions. Magahi, like major
Indic languages such as Hindi and Bangla, show morphological marking to
realize causativization of a verb (haT �move� -> haTaa
�move� -> haTbaa �cause (somebody) to move something�).
Causativization of verb has significant syntactic and semantic consequences
and scholars have worked on this topic for various Indian languages (Kachru
1973, 1976, Amritavalli 2001, etc). In this paper, I attempt to examine the
process of causativization in Magahi. I look at the morphological processes
involved in causativising a verb and also the properties of various arguments
in causative constructions in Magahi. The most common morphological marker
for causative is a suffix �baa (dauR �run� -> dauR-baa
�to cause to run�) but there are also variations (dauR �run� -> dauRaa
�to cause to run�). I attempt to show that this variation can be semantically
explained. In the first case, the causer is close/direct whereas in the
latter case, the causer is distant/indirect. In the second case, there is
also a scope for an extra argument whereas in the first one there is a single
causer (1). This distinction is not available to all the verbs. For instance,
in the case of gir �fall� -> giraa �drop/cause to fall/fell�
-> girbaa �make (s.b) cause (s.b) fall�. Wh-Questions in Sinhala
M.
G. Lalith Ananda Centre for Linguistics, SLL&CS, Jawaharlal Nehru
University, New Delhi E.
Mail: mlalithananda@yahoo.com This paper aims to discuss
WH-Question phenomena of Sinhala in Root, Embedded, and Yes/No questions with
special emphasis on certain syntactic and morpho-syntactic operations that
seem to interact with a number of other modules of grammar. In particular, it
will examine the role of verb morphology in WH questions, types of movement,
the relation between WH and Focus, and D-Linked WH phrases and will also
attempt to integrate the Sinhala WH-facts in to the cross-linguistic typology
of WH phenomena. As shown in example (1), WH in Sinhala displays the
following characteristics of whose configurations lead to different syntactic
and semantic representations. (soodanava �wash�, soodanna
�to wash�, seeduwa �washed�, seeduwE �E- form�) 1) ��Ravi�����
mokak�� da seeduwE? ������ ������ What did �
Question
word remains in-situ �
Question
word is followed by Q-morpheme �da� �
E-marking
of the verb The paper will argue that Sinhala WH-facts
motivate both overt and covert movement, overt movement being restricted to
partial WH movement in the embedded periphery. In particular, it will be
shown that the relevant heads for WH operations in Sinhala are FORCE,
INT(ERROGATIVE), and FINITENESS that constitute the left periphery as
proposed� by Cinque (1997, 1999). It
will also be argued that the E-morphology of the verb interacts with
Pragmatics making a distinction between De Re/De Dicto reading thereby
showing more evidence for Syntax-Pragmatics interface. A significant
generalization that surfaces in the study is that the left periphery of South
Asian Languages is more articulate than had been once assumed as shown by
Wh�in situ, a disjunctive particle, and a Quotative that can occupy the same
clause. Another generalization is that Sinhala WH always has covert movement
just like any other SOV language like Chinese or Japanese. Crosslinguistic Semantic and Translation Priming in Normal
Bilingual Individuals across Gender
Pravesh
Arya, Akanksha Gupta, & Brajesh Priyadarshi All India Institute of Speech and Hearing, Mysore E. Mail: pravesh_arya_here@yahoo.co.in;
akanksha041184@yahoo.co.in; brijesh_aiish@gmail.com INTRODUCTION The terms bilingual is used to describe comparable
situations in which two languages are involved. A bilingual person, in
the broadest definition, is one who can communicate in more than one
language, be it actively (through speaking and writing) or passively (through
listening and reading). ����������� Potter, Von Eckardt and Feldman (1984)
proposed two models i.e. Word association model and Concept mediation model,
to understand the nature of a bilingual�s semantic memory, where former model
states that lexical representations from language 1 are directly linked to
the conceptual system whereas, the words of language 2 are connected only to
language 1 and have no direct connections to the conceptual system and later
model suggests that representations of the two languages are not directly
connected and operate as separate systems that are directly connected to the
amodal conceptual system. To understand whether a bilingual�s semantic
representations are linked across the two languages researchers have
frequently used the semantic priming method. Semantic priming is based on the
premise that , upon presentation of a word, the corresponding concept and
associated conceptual nodes are automatically accessed. ����������� Several
studies have examined the nature of crosslinguistic and semantic priming in
normal bilingual adults. Some investigators used bilinguals who acquired L2
sometime between childhood and adulthood (Chen & Ng,1989; Kirshner et al;
1984) while others studied those who learned L2 during adulthood (Frenck and
Pynte,1987) As for translational priming in early
bilinguals, all experiments reviewed reported significant transition priming
in the L1-L2 direction while only one-third found significant translation
priming in the L2-L1 direction. The trends are similar in the late
bilinguals, i.e robust L1-L2 priming and less consistent L2-L1 priming.
Overall, the translation priming data suggest that L1-L2 priming is very
robust and that early and late bilingual process L1 primes in a similar way
but what differentiates the group is performance in processing L2 primes.� Results of a recent study done
by� Kiran,
Swathi; Lebel, Keith R.(2007) on Semantic and Translation Priming in
English �Spanish normal bilingual individuals and bilingual aphasics ,showed
that there was no difference
between translation and semantic priming effects for normal group and two
participants among 4 participants�
demonstrated greater priming from Spanish to English whereas two
participants demonstrated the opposite effect. AIM : Aim of the study is to examine crosslinguistic semantic
and translation priming during lexical decision task in Hindi-Kannada
speaking normal adult male and female bilingual individuals. The present study is aimed to answer the following
research questions that are-
METHOD �Participants A total of 24 Hindi-Kannada speaking normal bilingual
individuals (12 male and 12 female; age range- 18 to 30 years) will be
participated in the study.Participants�
will be selected on the criteria of having normal or
corrected-to-normal vision and no known reading or learning disorder. All
participants will be having no neurological and medical histories. Tools �All testing will be
done on IBM-compatible notebook computer with an Intel-Pentium processor,
running Windows XP and loaded with DMDX software(foster & foster,1999). Procedure Two prime �target relationship will be developed :
semantically related pairs and translation pairs. Twenty� critical words list will be prepared for
all critical word pairs. Each word will be paired with a semantically related
word to form 20 semantically related SR ,for e.g cat (�billi� in hindi)- dog (�nai�
in kannada ) word pairs. All word pairs will
be contained one Hindi and one Kannada word. Further, one half (10) of the
word pairs will be containing a Hindi prime and a Kannada target (H-K) and
the other half will be containing a Kannada prime and a Hindi target� (K-H) to balance language direction. To
examine translation priming, each of the 20 target words will be paired with
its corresponding translation TR for e.g cat
(�billi�in hindi )- cat(
�beku�
in kannada) , one half the word list
will be Hindi-Kannada and other half Kannada �Hindi. Using the stimuli discussed above,different versions of
the testing will be created. Within each version, each participant will be shown
40 word pairs presenting in random order : 10 crosslinguistic semantically
related (SR), 10 crosslinguistic�
unrelated (SU) 10 translation pairs (TR), 10 translation unrelated
(TU), within each of these above conditions , there will be equal numbers of
word pairs in each direction (Hindi-Kannada and Kannada-Hindi). To
counterbalance the language seen first by each participant, initial versions
of the experiment will be started with Hindi primes and later versions will
be started with Kannada primes. Two practice versions will be created using 5
word pairs. Results
and discussion: This section of the study will
be discussed later. REFERENCES: -Chen,H.C.,&Ng,M.L.(1989). Semantic facilitation nad
translation priming effects in Chinese-English bilinguals.Memeory and cognition,17,454-462. -Frenck,C.,&Pynte,J(1987). Semantic representation and
surface forms: a look at across language priming in bilinguals.Journal of Psycholinguistic Research,16,383-396 -Kiran S.& Lebel
K.(2007).Crosslinguistic semantic and translation priming in normal bilingual
individuals and bilingual aphasia.Clinical Linguistics &
Phonetics,21,277-303. --Poter,M.c.,So,K-F.,Von
Eckardt,B.,&Feldman,L.B.(1984). Lexical and conceptual representation in
beginning and proficient bilinguals. Journal
of verbal learning and verbal Behavior,23,23-48. Enhancing Students Writing Ability through Task Oriented
Responses to Listening Exercises: The Case of Pre-University Students in Iran
@Mahan
Attar and *S.S.Chopra @
Research student, Department of English, University o Pune, Pune-India. [Ministry
of Education, Hamedan District, Hamedan, Iran] E. Mail: attarm@yahoo.com *
University of Pune, Pune, India. E.
Mail: silloochopra@hotmail.com ����������� Writing
skill as one of the crucial aspects of communication is an obstacle for many
students. It is a complex process which requires attention to spelling ,
punctuation ,choice of words , sentence structure and a number of other
aspects . � ��������� Some methodologists such as Celce -
Murcia (1991), have suggested the task-oriented response to listening
exercises in order to involve the learners in language learning, more
communicatively. According to Celce � Murcia, there are two basic types of
students responses in listening exercises: 1) The question-oriented response
model. 2) The task -oriented response model. In question-oriented response
model students are asked to listen to an oral text, then answer a series
of factual comprehension questions on the content. In task -oriented
response model students make use of the information provided in the
spoken text, not as an end in itself but as a resource to use. ����������� This paper looks at pre-university
EFL learners in Iran and describes a research project which involved the
implementation of task oriented vs. question oriented responses to listening
exercises, designed to enhance students� writing ability. Quantitative analysis performed on
the data suggests that the task oriented responses to listening exercises is
more effective than question oriented responses in promoting writing ability
of Iranian students. Data
N = Number of students����������������������������������������������
SD = Standard Deviation ������������� M = Mean������������� ���������������������������������������������������������T
=� tobserved Table 1 The data derived from writing Pre test�����������
�� ��������Experimental group�������������������� 25����������� 44.9��������� 12.6��� �����������������������������������������������������������������������������������������������������������������������������
0.29 ���������� Control group��������������� ���������������25���������� 43.85������� 12.55
Table 2 The data derived from writing Pre test�����������
���������� Experimental group�������������������� 25����������� 67.9���������� 9.2��� ��������������������������������������������������������������������������������������������������������������
���������������3.52 ���������� Control group������������������������������ 25���������� 54.65������� 16.35
References Bahns, J.,
(1995). There�s More to Listening than Meets the Ear (respective review
article.) System 23(3):531-547� � Canale M, Swain M.
�Theoretical bases of communicative approaches to second language teaching
and testing�. Applied Linguistics (1980) 1(1):1�47.[Medline]��������������������� Celce_Murcia , M.
(1991). Teaching English as a second or Foreign Language. 2nd
ed. California: Heinle and Heinle Co. Hymes D.
�On communicative competence� in J. B. In: Sociolinguistics�Pride,
Holmes J, eds. (1972) Harmondsworth: Penguin Lynch,T
.(1996).Communication in the language classroom. Oxford : Oxford University
Press.��� Nunan,D. (1989). Designing tasks for the communicative
classroom. Cambridge : Cambridge University Press. Wilkins, D. (1976). Notional syllabuses. Oxford: Oxford
University Press. Phonological, Grammatical and Lexical Interference in
Adult Multilingual Subjects
Avanthi.
N & Abhishek. B.P & Deepa M.S. J.S.S. Institute of Speech and Hearing, Ooty Road, Mysore E. Mail: avanthi.niranjan@gmail.co; abhishek.bp@gmail.com;
deepalibra@gmail.com INTRODUCTION: Bilingualism
is defined as using or knowing more
than one language (can be more than two languages); so every bilingual person
is also multilingual, but the contrary is not necessarily true.. Language
interference is the alternative use by bilinguals of two or more languages in
the same conversation. Language interference is a linguistic practice
constrained by grammatical principles and shaped by environmental, social and
personal influences including age, length of time in a country, educational
background and social networks. The ability to switch linguistic codes,
particularly within single utterances requires a great deal of linguistic
competence. Interference of L1 on L2 occurs
in many components levels like phonological, lexical, grammatical.
Researchers argue that transfer is governed by learner�s perceptions about
what is transferable and by their stage of development in L2 learning. In
learning a target language, learners construct their own interim rules. �AIM: To analyze the different types
of language interference (Phonological, Grammatical and Lexical) in multi
lingual adult speakers. METHOD: The
method was designed to uncover something of the complexity of language use in
a particular sample of language learners and so it had an explicit
descriptive purpose.� 20 multilingual subjects were considered in the age range
of 21- 22 years of age. Among which 10 subjects were native Kannada speakers
and the other 10 subjects were non native Kannada speakers (Malayalam,
English and Kannada). 3 tasks
were considered Conversation, Narration and Picture Description. All
the three tasks were carried out in Kannada for both the groups (Native &
Non Native Speakers). Analysis was done for content and
complexity of language. The
data were transcribed verbatim, with verification for accuracy. To prepare
the transcribed data for analysis, repetitions, false starts and irrelevant
speech were deleted. The basic unit for segmenting the data was the T unit,
defined as one independent clause plus the dependent modifiers of that
clause. �The narrative discourse tasks in the
study were analyzed in terms of sentential grammar, discourse grammar and
subjective quality. RESULTS AND DISCUSSION: Analysis was done in 2 steps, analysis of content and
analysis of complexity. The analysis of content was
grouped under 3 measures, Phonological, Grammatical and Lexical. The analysis
of complexity was done by using T unit based analysis. To depict relationship
between the scores of native and non native Kannada speakers, paired
comparison t test was carried out for Narration and Picture Description
tasks. There was highly significant statistical difference between the two
groups considered, in terms of number of T units, number of Clauses / T unit,
number of words/clause, number of words/ T unit, number of Clauses, number of
Irrelevant clauses and number of words/ irrelevant clauses. The statistical
analysis indicated that difference was found in all the measures considered. The results are indicative of, the content and
complexity seen in the non native speakers is distinctively different from
the native speakers. And the interference is explained in the content part of
the study and the phrase length, compleixity of utterance which is the
reflect of the language proficiency is explained in terms of the T units. CONCLUSION: The study aimed at assessing the qualitative and
quantitative differences in the non native speakers of the language, their
proficiency of language and the different types of influence or transfer of
the dominant language to the non native language. The results also indicate
that there will be considerable influence or borrowing of features from a
language that is learnt earlier or used more excessively in one�s social
context. In the present study, the
phonological, grammatical and lexical interference were studied. Further the
study can be extended by studying the influence of both L1 and L2 on L3� separately, analysing stress, rhythm,
intonation of the non native language can be done objectively and can be
compared with the native language, and studying more complex structures of grammar
of non native language. REFERENCES: Sima Paribakht. T., December (2005). The Influence of
First Language Lexicalization on Second Language Lexical Inferencing : A
study of Farsi � Speaking Learners of English as a Foreign Language. Language Learning, 55:4, 701-748. Baljit Bhela, 1999. Native language interference in learning a
second language: Exploratory case studies of native language interference
with target language usage. International
Education Journal, Vol 1, No 1. Ellis, R. (1994). Factors in the Incidental Acquisition of Second
Language Vocabulary from Oral Input: A review essay. Applied Language
Learning, 5(1), 1-32. Frederika Holmes (1999). Cross-language interference in lexical
decision. Department of phonetics and
linguistics, Vol. 12 (2), 380-398. Faerch, C. &
Kasper, G. 1983, �Plans and strategies in foreign language communication�,
in Strategies in Interlanguage Communication, ed. C.
Faerch and G. Kasper, Longman, London. Poulisse, N. (1993). A
Theoritical account of Lexical Communication Strategies. The bilingual lexicon. Vol. 32, 157 � 189. Ecke and
Herwig (2001). Linguistic transfer and the use of context by Spanish �
English bilinguals. Applied
Psycholinguistics, 18, 431 � 452. Yu, L.
(1996a). The role of crosslinguistic lexical similarity in the use of motion
verbs in English by Chinese and Japanese learners. Canadian Modern Language Review, 53(1), 190 � 218. Comparative Study of
Nagpuri
SUNIL
BARAIK Deptt. Of Tribal & Regional Languages of Jharkhand,
Ranchi University, Ranchi E.
Mail: s_baraik_in@yahoo.com Nagpuri is the Mother-tongue of ChikBaraik as well as 9
other tribes of Jharkhand. In this state many ancient tribes like Munda,
Oraon, Kharia, Chik Baraik and the total of 32 tribes dwell together
peacefully, all from different language groups (Austro Asiatic, Dravidian and
Indo Aryan). It is also the pidgin of Jharkhand. Almost all the tribal people
speak Sadani with some local variation. It is used by a large section of
tribal as well as non-tribal population either as a Mother tongue or as
lingua franca. There are different views regarding the origin and status of
Nagpuri. According to the Encyclopedia Mundarica, Sadri is the language of
Sadans It is also used as a Mother-tongue among some Munda, Oraon and Kharia
families residing in some parts of Simdega, Gumla, Lohardaga, Hazaribagh,
Ranchi and Khunti Districts. Apart from Jharkhand, Nagpuri is also spoken in Assam, West Bengal, Orissa,
Chhatisgarh and Bhutan where the people of Jharkhand migrated to earn their
living. In those places this language is also known as Sadri, Sadani, Gawari,
Nagpuri, Nagpuria and even Jharkhandy language. It is observed that almost
all the Oraons know this language. It is said that Oraons were banned of
using their Mother-tongue (ie; kurukh) in Chotanagpur by the kings. Hence
they were forced to adopt Nagpuri as their mode of communication because it
was the (Rajbhasha) official language of Chotanagpur at that time. Though the Oraons adopted this language as means of
communication, they also mixed some other tribal as well as Hindi words.
Nagpuri spoken by the Chik Baraiks is pure and is very much distinct from the
others. Nagpuri spoken by Chik Baraik tribe and Oraon tribe can very easily
be differentiated. My paper will be based on the comparative study of Nagpuri
spoken by Chik Baraiks and Oraons of Jharkhand. A Comparative Study of
Reduplication in Gujarati and Telugu
Asma
I. Barodawala & T. Sree Ganesh Central Institute of Indian Languages, Mysore This study aims at a comprehensive but at the same time
concise account
of the functions of reduplication across Gujarati and Telugu.
Reduplication is understood as
syntactic reduplication as defined by Wierzbicka (1986). While recognizing the origins of
reduplication in discourse, clausal and intraclausal repetition, universally
used pragmatic
devices, are excluded from this study. Likewise,
reduplication involving full
copies will be at the center of the analysis while partially reduplicated forms are considered
to be variants
eroded from fully reduplicated ones. Complete
Reduplication: GUJ: �� ઉભા ઉભા� ������������������ /ʊbʰa ʊbʰa/�� ��������������� �standing
standing� TEL: �� నిల్చుని నిల్చుని� ��������� /niltʃuni niltʃuni/��������� �standing
standing� Partial
Reduplication: ����������� ������ GUJ: �� રમત ગમત����������������� /rəmət
gəmət/������������� �playing
and things like that�������������� TEL:���� ఇల్లుగిల్లు���������������� ��� /illʊ gillʊ/�������������� ����� �house and things like that� Although reduplication can be
argued to constitute the least marked morphological
process (Couto 2000). The second
and perhaps more important
goal of this paper is to unearth the patterning of
reduplication in Gujarati and
Telugu. It is argued that in spite of the universality of reduplication,
substrate influence plays a crucial role
in determining the exact functions of reduplication. This
hypothesis is corroborated by my
findings from the study of the partly overlapping area of ideophones (Bartens
2000) which will be discussed as
a speacial category of reduplicated items in some of the creoles
under survey. Naming Deficits in
Bilingual Aphasia
Ridhima
Batra & Pallavi Malik & Shyamala K.C All India Institute of Speech and Hearing, Manasagangotri,
Mysore � 06 E.
Mail: canif_ridhima@yahoo.com; charuthecharm@yahoo.co.in;
shyamalakc@yahoo.com INTRODUCTION Naming calls into play multiple levels
of processing. When used in conjunction with other basic tasks, it is usually
possible to determine whether the principal cause of naming deficits are
perceptual, semantic, or language output impairments. Naming of a visual
stimulus such as an object or picture begins with early visual processing and
recognition. The process of confrontation naming requires the formation of a
perceptual representation of the object. It requires access to some sort of
semantic representation to specify the concept that will then be tagged with
the correct verbal label. Bilingualism is an intriguing
phenomenon and has been defined variously by different authors. According to
Fabbro (1999) people who speak and understand two or more languages and
dialects are referred to as bi/multilinguals. Aphasia in a multilingual can
lead to different language deficits in the languages known and is called as
bi/multilingual aphasia. Naming deficits in aphasia are
seen as retrieval failures which take different forms, depending upon the
stage at which the breakdown occurs. A failure to retrieve the target lemma
results either in selection of another lemma that has a similar semantic
description i.e., semantic paraphasia; or a failure to retrieve a word�s
phonological description i.e., phonological paraphasia in which the word
sounds like the correct word but sounds are substituted, added or rearranged;
or a neologistic paraphasia with a production of a non-sense word. Paraphasias are common in aphasia and can help
differentiate fluent from non-fluent aphasia. AIM: To examine naming deficits in bilingual aphasics and
highlight the variation/correlation of these across languages. METHODOLOGY SUBJECTS:
6 Kannada-English Bilingual aphasic subjects were taken for the study. All
the participants were males. SUBJECT SELECTION CRITERIA: v Types of aphasia: Both fluent and non-fluent aphasic
syndromes were considered which was decided on the basis of clinical
observation and WAB-K (Kertesz & Poole, 1982) findings. Three fluent (2
anomic and 1 Wernicke�s) and three non-fluent (2 Broca�s and 1 Transcortical
motor) aphasics were taken for the study. v �Age range: 25-50
years. v All subjects were right handed which was determined using
self-report and information from significant others. v Subjects had Kannada as their mother tongue and had learnt
English as second language before the age of 10 years. v Subjects with any auditory or visual deficit were excluded
from the study. v Ethical considerations were met. PROCEDURE: Subjects
were seated comfortably. Then by casual talking, the subjects were made to
feel at ease and the procedure was explained before the evaluation and
recording began. The environment was made as distraction free as possible by
carrying out the procedure in a quiet room and by removal of any potential
visual distracters. The entire verbal interaction with the subjects was audio
recorded using Wavesurfer 6.0software. TEST ADMINISTERED: Naming
section of Western Aphasia Battery (Kertesz & Poole, 1982) was administered
in both Kannada and English language. ANALYSIS: The
naming section of WAB, for all the subjects in both the languages was
transcribed and analyzed for the presence of paraphasias (semantic,
phonological paraphasias and neologisms). Variation of paraphasias among the
fluent and non-fluent aphasic group and language specific errors in them were
identified and described. STATISTICAL ANALYSIS: Appropriate statistical measure was used for both
qualitative and quantitative analysis of the data. RESULTS
AND DISCUSSION: The type of naming deficits
exhibited by the fluent and non-fluent bilingual individuals with aphasia
will be discussed in detail, in the paper. REFERENCES Fabbro, F. (1990). The Neurolinguistics of Bilingualism-
An Introduction. London: Psychology Press. Kertesz, A., & Poole, E.
(1982). The aphasic quotient: The taxonomic approach to measurement of
aphasic disability. The Canadian Journal of Neurological sciences, 1, 7-16. Voicing patterns in Indian
English
Pratibha
Bhattacharya Department of Linguistics, University of Delhi, Delhi E.
Mail: thepratibha@yahoo.co.in The present study aims to understand and account for the
variability that exists with reference to voicing patterns as in the
following categories: a)
Plural
allomorphs (such as /s/ in [kQt-s] �cats� ;/z/
in [bQg-z] �bags�; /Iz/ in [mez-Iz] �mazes�) b)
Possessives
(such as �black buck�s legs� in the sentence �The black buck�s legs are
broken�) c)
3rd
person singular forms (such as �loves� in the sentence �He loves
that girl�) in English language in Delhi, India (commonly referred to as
Indian English). The paper also attempts to explore various possible
linguistic factors (acoustic phonetic, phonological and morphophonemic
factors) that are known to influence voicing. The
commonly assumed understanding of the three plural allomorphs of English (the
standard version) [s], [z] and [Iz] is that, these allomorphs
differentiated by the voicing or lack of it are induced by the final
consonant of the singular form of the noun as shown below. a) cat-s [kQt-s] Plural � [s] /���� C��������
----------------���� # ������������������ [- voice]������ [Plural] b) bag-s [bQg-z] Plural � [z]��
/����� C�������� ------------------�� # ��������������������� [+ voice]����� [Plural] c) maz-es [mezIz] �Plural� [Iz] /������� C��������� ---------------- # ������������������� [sibilants]��������� [Plural] ������������������ [palatals] The need for exploring the voicing pattern is to ascertain
to what extent English in India follows the same pedagogical rule as
described above. In the present context, it refers to the consonants in
Indian English and their ability to induce voicing in the adjacent
environments. It must be mentioned that �Indian English� is an umbrella term
that covers several varieties of English used as a second language in India.
These varieties are generally assumed to exhibit significant phonological
variations, stemming from various regional linguistic differences.� Yet the results of the present study show
remarkable stability in voicing patterns and the contributory factors across
speakers in the sample. The study is based on data
comprising spontaneous speech and data obtained through reading tasks such as
word-lists, sentences and texts collected from a sample of 15 people born and
brought up in the city of North and North-West Delhi and who belonged to the
age group of 25 to 30 years. Resultative and Stative in
Bangla: How different?
Shiladitya
Bhattacharya University of Calcutta, Kolkata In Bangla we can have three different
semantic readings of Event, State and Result in passive constructions. In
Eventive Passive constructions there should be an agent who will be
performing the action where as in both Resultative and Stative readings there
is absence of an clearly indicated agent which makes them both different from
that of Eventive .Now when we look at the Resultative and the Stative
readings what we can mark as an essential difference between those is
that-the Resultatives have an indication to a result that is caused by an
action(which is done previously, by some agent may� not be as clear as the Eventive reading
which has got a mandatory agent.).On the other hand in the Stative
interpretation of a sentence we find only the state of a thing/object/entity.
So in brief the distinction among the three can be put like this. Eventives
have a mandatory agent, Resultatives may or may not have an agent (i.e. the
action may be without a direct agent to say a voluntary or self agentive
action or it may have an agent which is not as clearly understandable as that
of an Eventive one) and the Statives express the state of thing/object
/entity (the presence or absence of the agent is not important). Our problem with Bangla is that
the two readings of Stative and Resultatives are sometimes phonetically
similar. In most of the cases when copula is dropped from the Resultatives
the two phonetic forms becomes similar and thus hard to distinguish. Examples
are given below. And it will be necessary to mention here that in case of
some verbs this difficulty arises. We are yet to make generalization that all
the verbs show the same phenomenon. In colloquial Bangla, the copula drop
from Resultatives is a common phenomenon and so the aim of this paper will be
to try to distinguish between these two readings at the conceptual level with
the help of some syntactic tests or devices.��� �Bangla Passive
constructions have a clear distinction between its 1. Eventive and 2. Stative
and /or 3. Resultative readings. But, the real problem, as explained
above� is to differentiate between its
(the Passive construction) Stative and Resultative readings as in most of the
cases their phonetic forms are similar. E.g.
Eventive:����� /d�rj(a����� khola������ holo/ ���������������������������� Door������ open�
����happen-past ��������������������������� �The door was
opened.� ���� Resultative:���� / d�rj(a����� khola������ / ������������������������������ Door����� open-present ����������������������������� �The door is
opened.� ���� Stative:���������� / d�rj(a �����khola������ /������� ( /khola�� d�rj(a / � the opened door� is an ����������������������������� Door������ open������������������� Adjectival Use) ����������������������������� The opened
door.� E.g.
Eventive:���� /dorja������ bondho������ holo/ ���� ������������������������Door������ close��������� happen ��������������������������� �The door was
closed.� ������� Stative�� :����
/bondho������� dorja/ ���������������������������� Closed�������� door ���������������������������� �Closed door� ����� Resultative:��� /bondho���
kora��������� dorja/����� ���������������������������� Closed����� do-inf.����� door ���������������������������� �Closed door.� ������������������� or ��������������������������� /bondho����� dorja/ ��������������������������� closed�������� door ��������������������������� �Closed door.� The
aim of this paper will be to try to identify any diagnostic procedure(s) that
can provide a clear distinction between the two readings (Resultative and
Stative) in Bangla. Reference: Landau, Idan.� Unaccusatives, Resultatives and the
Richness of Lexical Representations.�
Paper downloaded from http:// ocu.mit.edu/ visited on 31.10.2008 The Indo-Portuguese Creole of Diu: �participant�, �alien�
or �observer� of the Indian Linguistic Area?
Hugo
Canelas Cardoso Universiteit van Amsterdam, THE NETHERLANDS E.
Mail: hugoccardoso@gmail.com The
Indo-Portuguese Creole spoken in Diu (U. T. Daman, Diu, Dadra and
Nagar-Haveli), like most high-contact varieties across the world, establishes
important typological links with the various languages which were involved in
its formation and/or with which it coexists. In the specific case of Diu
Indo-Portuguese (henceforth DIP), the early days of contact, in the early
16th-century, involved Kathiawadi Gujarati and Portuguese. However, it is
likely that other codes also contributed to the initial `feature pool'
(Mufwene 2001), including possibly previously restructured varieties of
Portuguese, and neighbouring Indian laguages. In highly multilingual India,
examples of extreme linguistic convergence through contact are hardly
uncommon (recall the well-known case of Kupwar village, described in Gumperz
& Wilson 1971) but, unlike most such cases, the formation of the
Indo-Portuguese Creoles did not involve strictly languages which
traditionally participate of the Indian Language Area (henceforth ILA). It is
my purpose to ascertain to what extent the admixture observed in DIP has
brought it into the realm of the ILA by investigating its (non-)conformance with
the defining or salient typological characteristics identified for the ILA
(Emeneau 1956, Masica 1976, Subbarao 2008). This study reveals that DIP aligns with its primary
ancestor languages (Gujarati and Portuguese) in ways that are often difficult
to predict, and also that it is very difficult to try and rank the influence
of one language with respect to the other. A systematic comparison shows
that, alongside its links with Gujarati (e.g. case assignment) and Middle
Portuguese (e.g. basic word order), the (modern variety of the) Creole
diverges from both other domains (e.g. the relative absence of inflectional
morphology) - which raises important questions concerning the process of
creolization, on the one hand, and the exact composition of the initial
`feature pool', on the other. References Emeneau, Murray B. 1956. �India as a linguistic area�. Language 32:3-16. Gumperz, John J. & Robert Wilson. 1971.
�Convergence and creolization: A case from the Indo-Aryan/Dravidian border�. In
Dell Hymes (ed.), Pidginization and creolization of languages.
London: Cambridge University Press. pp. 151-67. Masica,
Colin P. 1976. Defining a linguistic area: South Asia. Chicago:
University of Chicago Press. Mufwene,
Salikoko. S. 2001. The ecology of language evolution. Cambridge:
Cambridge University Press.���� Revised Receptive Expressive Emergent Language Scales for
Kannada Speaking Children
Deepa
M.S., Madhu K, Harshan K & Suhas J.S.S. Institute of Speech and Hearing, Ooty Road, Mysore E.
Mail: deepalibra@gmail.com INTRODUCTION : Language development is a process that starts early in
human life, when a person begins to acquire language by learning it as it is
spoken and by mimicry. Child language development move from simplicity to complex.
Many tests have been developed for language in toddlers. Even though they
have been developed many decades back, they are still in practice in almost
all clinics in India. But the tests need to be revised because children are
observed to be developing many skills at very early age. AIM: To revise the REELS (Receptive
Expressive Emergent Language Scales) for children exposed to Kannada
language. METHOD: 720 children from all over
Karnataka with age range of 0-3yrs served as subjects for the study. The
children were divided into different age ranges 0-3 months to 33-36months.
The milestones in REELS both receptive and expressive skills were numbered
and used for the study as questionnaire which was administered to the
parents/caregivers. The responses were tabulated and analyzed. RESULT AND DISCUSSION: The results collected from all
three regions were gathered and standard deviation was calculated. To
rearrange milestones 80%criteria was used. If 80% of children are passing a
particular milestone that milestone stone is shifted to the lower age groups.
There was highly significant difference seen in 1st to 3rd
year but the milestones did not differ significantly in the lower age group
that is less than 1 year CONCLUSION: Results revealed that there was significant
difference seen in second to third year of life than in first year, both in
reception and expression. So the revised REELS contain the skills which have
been shifted to lower age group using 80% criteria. But the scale need to be
administered to clinical population and has to be checked for validity. Also
there is unequal number of skills in each age range, equal number of skills
has to be distributed and revised further. REFERENCES American academy of
pediatrics.,(1980). Caring for your
baby and young child: Cambridge UK. 213-224. Anerew, N.M., Freckerit, Z.,(2007)
Association between media viewing and
language development in children under 2 year age: Washington DC: Author. �92-100. Anisfeld, M.,(1979) Interpreting "imitative" responses in early infancy. Science, 214-215. Aslin, R.N., & Pisoni, D.B.,(1980) "Effects
of early linguistic experience on speech discrimination by infants: " Child
Development, 107-112. Bzoch, K., League, R. and Brown, L. (2002) REELS (receptive expressive emergent language scale) 1st
and 3 rd edition. Caroline,
B. (1998), Typical Speech Developmen: Washington DC: Author..240-253 Elisabeth, H., Yousef, E. (2000) Developing a
Language Screening Test for Arabic-Speaking Children. Harlekar, G.(1987)
3-Dimensional language test Johnson, C.J., & Anglin, J.M. (1995) Qualitative
developments in the contents and form of childrens definitions. JSHR,
28:612-629. Moog, J.S., and Geers, A.V. 1975. Scales of early communicatin skills (SECS) Nippold, M.A. (1998) Later language development. The
school age and adolescent year.
Cambridge UK. 219-240 Natson, R .(1985) Towards a theory of definitions, Journal of child language development,
12:181-197. Prathanef, B., Pongajanyakul, A., (1998) International journal of language &
communication disorders.41, 214-120 Reed, V. (1992)� Introduction
to child language disorders (1995). Springer� publishers. 345-356. Relationship between Symbolic Play, Language and Cognition
in Typically Developing Kannada Speaking Children
Devika.M.R,
Navitha U & Dr. Sapna N. All India Institute of Speech and Hearing, Manasagangotri,
Mysore � 06 E. Mail: dvkspdevika@gmail.com; naviudew@gmail.com Introduction:
Play is defined as any voluntary activity engaged for the enjoyment it gives
without consideration of the end result (Piaget, 1962).� Play serves as a
platform for social interaction (including co-operating with each other and
working together towards a goal, turn taking, decision making, problem
solving etc.), emotional, motor, cognitive and language development. It
combines action, language and thought (Tassoni & Hucker, 2005). Symbolic play is one of the surface
manifestations of symbolization. Symbolization is the fundamental process of
cognitive development.� Play develops
throughout a child's life, and it evolves from simple physical manipulation
of objects to sophisticated and planned sequenced play. The ability to play
symbolically emerges during the second year of life. For many
years, language pathologists, psychologists and other researchers have tried
to discover evidence for the linkage between language, play and
cognition.� In the west, many studies carried out on typically developing children
evidenced mixed results, some which confirmed the fact that there is a
correlation between symbolic play and language(McCune-Nicolich, 1981, Ogura
1991).Lyytenin, Laakso(1997) and Chik Hsia Yu Kitty (2000), others which
showed no significant relationship between symbolic play and language,
particularly mean length of utterances (MLU) Shore, (O-Connell and Bates
1991) In addition, there are limited studies which investigated the
relationship between play, language and cognition especially in the Indian
context. Hence it becomes necessary to study the correlation between these
three skills in typically developing children.� Objectives: Is there any relationship between
symbolic play, cognition and language development in typically developing
children? Does play correspond with the language comprehension and/or
expression? Method: Subjects: The sample included 10 typically
developing Kannada children in two different age groups 24 to 30 months and
30-36 months. Subjects were mainly recruited through nursery, kindergartens.
Each group consisted of 5 subjects with close to equal number of males and
females in each group. The children included in the study had no history of medical problems, emotional, behavioural or
sensory disturbances. Each child was administered Three-Dimensional Language
Acquisition Test (3D-LAT) (Geetha
Harlekhar, 1986) to
assess their receptive, expressive and cognitive skills. Assessment checklist
for play skills (Swapna, Jayaram, Prema, Geetha, in progress) was
administered to get the age equivalent play scores. Procedure: To study the symbolic play behavior, two sessions of play
were organized in which all the children participated in two types of play
situations viz. free play and structured play. The play sessions were video
recorded. Structured
play: Each child was presented with
four sets of thematically related toys, one set at a time, and they were
allowed to interact with them for approximately 5 minutes each. The sets
included several standard toys which would facilitate symbolic play and
either a stick or a block as an item to be transformed. Free
play: Each child was presented toys such
as kitchen set,furniture set,doll,quilt .truck,tool kit etc which were spread
in the vicinity of the child. The child was�
invited to play with the toys. The mother was seated in the room but
was asked not to intervene in the child�s play. This session lasted for
approximately 10 minutes. The symbolic play behaviours such as functional play,
sequential play and verbalized elaborate play were studied The qualitative
differences in symbolic play and the frequency of symbolic play in the two
different age groups were analyzed. The play behaviors observed during the
free and structured play was used to rate the assessment checklist for play
skills. This was done in addition to the information obtained about the play
behaviour though parental interviews. Based on the observations made the age
equivalent scores for play were calculated. During free play, the toy
preferences also were noted in terms of the toys that are reached out first
and the duration of play with a specific toy. Gender differences were also
studied. Results: Appropriate
statistical analysis was applied to investigate the differences with respect
to the symbolic play patterns, the relation between symbolic play, language
and cognitive development, toy preference among both the groups and the
difference in genders. The findings indicated that there was a positive relationship
between the subjects' chronological age and play, language and cognitive age.
The data supported the hypothesis that symbolic play correlates with language
and cognitive development. The results will be discussed in detail with
respect to variables such as toy preferences and gender differences. The
developmental differences between various play behaviors are also discussed. Conclusion: The study of child language to describe and analyze
spontaneous production of spoken language, with a cognitive and pragmatic
framework contributes not only a more accurate understanding of normal play
and language development, but also has an efficient clinical value. This
suggests that play and language reflect the different underlying mental
capacities in the young child. Such information would contribute to the
assessment and diagnosis of children with communication difficulties. References: Bates, E., Benigni, L., Bretherton. I.,Camaioni, L.,&
Volterra, V.(1979).The emergence of
symbols:cognition and communcation in infancy. New York:Academic Press Chick Hsia Yu Kitty (2000)
�Correlation between symbolic play and language in normal developing
Cantonese speaking children.� Dissertation submitted as a part of partial
fulfillment for the bachelor of science, speech and hearing sciences.
University of Honk kong . Geetha
Harlekhar (1986) �Three dimensional language acquisition test (3D-LAT)�
unpublished dissertation,� speech and
hearing. Mysore university. McCune-Nicolich,
L. (1981). Toward symbolic play functioning: Structure of early pretend games
and potential parallels with language. Child
Development, 52, 785- 797. Piaget, J. (1962). Play,
dreams, and imitation in childhood. New York: Norton and Company Swapna, Jayaram, Prema, Geetha, (in progress), an ARF
project undertaken at AIISH, Mysore Tassoni, P., & Hucker, K.
(2005). Planning play and the early
years. Heinemann ELDP Data Collection: Some
Baram Experiences
Dubi
Nanda Dhakal, TR Kansakar, YP Yadava, KP Chalise, BR Prasain & Krishna Paudel Central Department of Linguistics, Tribhuvan University,
Kathmandu, Nepal E.
Mail: dndhakal@yahoo.com We have been documenting the Baram language, a language of
Tibeto-Burman language spoken in the western Nepal since May 2007. This
programme has been supported by ELDP (Endangered Languages Documentation
Programme), School of Oriental and African Studies, University of London and hosted
by Central Department of Linguistics, Tribhuvan University, Nepal. The
sociolinguistic setting of the language reveals that this is a seriously
endangered language when we assess the degree of language endangerment by
means of the criteria set by UNESCO (2005). There are about three dozens of
fluent language speakers, and only about a dozen of fluent language speakers
can actually contribute good texts for language documentation.� The language is not used for natural
communication. The task of collecting data is more challenging because the
Baram community does not use it in natural setting. We follow Himmelmann (1998) in the beginning to collect
the data which are more varied and functional. He explains that the
communicative events can be placed in a continuum. On the one extreme that
are spontaneous expressions like exclamation, or the expressions to show pain
and anger and on the other extreme there are expressions which are well
planned like the language used in ritual and so on. All sorts of human
communication is possible with different kinds of interactions between these
two extremes. Unfortunately, in the Baram language we did not find the use of
language in both of these extremes. The language is neither used at natural
setting nor is it used in the rituals. Taking Himmelmann (1998) as a departing point, we expanded
the inventory of communicative events covering several areas. We follow Lupke
(2005) while expanding the inventory. In order to have very restricted
structure of the language we follow Leech and Jan Svartvik (1994). They help
us get the paradigm for writing a sketch grammar. We also follow Franchetto
(2006:189) to collect data on ethnographic topics like celebration of
festivals, cultural occasions and so on. We may summarize the inventory of communicative events and
genres which are (1) Exclamative (cries, signs of surprise, joys etc (2)
Directive (ordering, permission, telling, vocative etc) (3) Conversational
(conversation, chat, discussion, interview, songs etc. (4) Monological
(historical, personal), myths, speeches and routines etc. (5) Rituals
(ritual, birth and death ceremony) etc. Due to the restricted use of language, we are unable to
have data for the genres like language of rituals, formulaic expressions like
greetings and leave taking and so on.�
We followed very rigorous method of data collection for this process
and finally succeed in collecting the representative corpus. Due to very limited language use, we also used stimuli
like documentary films, clips of songs, photographs, and some questions typed
on the laptop etc. We hope the methodology can be used while working with
severely endangered languages. In this paper, we are discussing various strategies used
in data collection. Aside from this, we also talk about different language
speakers and which area they can contribute. We find that some speakers can
contribute to the narrative texts whereas some others are useful in myths and
rituals. We have collected about 65 hours of texts including audio and video
recordings. Most of these files were recorded at our field office in Gorkha
which is located in the western part of Nepal.�� We suggest the following recommendations for field workers
based on our field work: (1) Make an inventory of different genres, communicative
events and ethnographic topics.� This
help you capture diverse sessions with different uses of the language. (2)
Work with different speakers. One may be good at narrating stories, another
at giving instruction and another perhaps at data elicitations for making
paradigms.(3) Make a proper analysis of data you have collected before you
record texts for hours! You will be surprised to see that the linguistic
contents of the speaker who speaks for a long time may be worthless! (4) Make
your sessions of moderate length. If they are very long, i.e. for an hour,
they may be difficult to handle in some computer softwares like ELAN,
TOOLBOX, AUDACITY when these files are edited and annotated. (5) Record some sessions
which are directly related to grammar, i.e. 'conditional clause', 'purposive
clause', etc. This helps you get the language in use while writing grammar.
(6) The language speakers should be properly trained before recording the
sessions if you intend to have specific topics and structures recorded. References: Abbi, Anvita. 2001. A Manual of
Linguistic Fieldwork and Structures of Indian Languages. Lincolm
Handbooks on Linguistics, No.17. Munchen: Lincom Europa.� Franchetto, Bruna. 2006.
Ethnography in language documentation. Essentials of Language
Documentation. (Ed) Gippert, Jost, Nikolaus P. Himmelmann and Ulrike
Mosel. Berlin and New York; Mouton de Gruyter. Grinvald, Colette. 2003. Speakers
and documentation of endangered language. 53-72. Language Documentation
and Description Vol. 1. (Ed) Peter K. Austin. Endangered Language
Project.� Himmelmann, Nikolaus. 1998.
Documentary and Descriptive Linguistics. Linguistics� 36:161-95. Leech, Geoffrey and Jan Svartvik.
1994. A Communicative Grammar of English. Singapore: ELBS.� Lupke, Fiederike. 2005. Small is
beautiful: contributions of field-based corpora to different linguistic
disciplines, illustrated by Jalonke. 75-105. Language Documentation and
Description Vol 3. (Ed) Peter K. Austin. London: Endangered Language
Project. Samarin, William J.1967. Field
Linguistics: A Guided to Fieldwork. New York: Holt Rinehart and sinston,
Inc.� Yavada, Yogendra P.1998. Lexicography
in Nepal. Kathmandu: Royal Nepal Academy.�
UNESCO. 2005."Safeguarding of
the Endangered Languages: The Endangered Language Fund Newsletter, 7:1. Some Methodological Observations on Linguistic Fieldwork:
Case Studies from the Maharashtra Karnataka Border
*Arvind Jadhav� &
#Nick Ward *Y C College
of Science, Karad. Distt. - Satara. Pin-415124 India (MS) #
University Of Sydney, Camperdown, NSW.
AUSTRALIA E. Mail:
lecturer.arvind@gmail.com; nwar3485@mail.usyd.edu.au Two
current case studies are used to illustrate some methodological considerations
in undertaking linguistic fieldwork. One is an investigation into the
language of the traditional Indian healing systems of Ayurveda and
Yog-therapy, as they are practiced in The
investigators have ample theoretical background and are in the process of
applying this theoretical knowledge to their fieldwork studies. Past
methodologies are discussed, and their applications to the present researchers�
work are considered and reflected upon. Case
study 1: In this study recordings of consultations between Ayurvedic
practitioners and Yog-therapists, and their patients are used as a basis for
investigating metaphor and figurative language within the formal linguistic
frameworks of these traditional practices in Marathi. The data are collected
from the Case
study 2: Language convergence process occurring due to prolonged language
contact situation has been a topic of interest and intense enquiry in
Sociolinguistics. Other than prolonged language contact situation, language
convergence occurs due to immigration and in the case of tribal languages. In
General
issues of linguistic fieldwork methodology are identified (as articulated,
for example, in Eckert, 2000; Rajyashree, 1986; Milroy 1987), and strategies
for addressing these issues are discussed with specific reference to the
above case studies. Amongst these general issues and challenges are the
following: 1. Selection of the locality for the study. 2. Consideration of what type of language required for
recording (e.g. Spoken or written; casual conversation or a more structured
format like a ceremony or ritual). 3. Entering the communication network, and the
implications of the chosen method. 4. Consideration of what specific things are to be looked
at in the language (e.g. lexical items such as slang words or address forms;
syntactic structures; pragmatic strategies, etc.), and how to elicit the
required forms. 5. Legal and ethical implications such as consent and
voluntary participation of respondents. 6. Self involvement of the primary investigators, and
dependence on assistants for certain purposes. 7. Methodological tools to be used and their
standardization. 8. Representation of all social variables, and
consideration of which variables
are relevant. This paper will employ a multi-disciplinary approach to
make a meaningful contribution to the fields of linguistic methodology, and
Indian language studies. REFERENCES: Barrett,
Robert J, and Lucas, Rodney H. 1993. �The Skulls
Are Cold, the House Is Hot: Interpreting Depths of Meaning in Iban Therapy�.
Eckert,
Penelope. 2000. Linguistic Variation as
Social Practice. Gumperz,
J.J. and Wilson, Robert. 1971. �Convergence and Creolization-A case from the
Indo-Aryan/ Dravidian border in Konitzer, M., Schemm, W.,
Freudenberg, N., and Fischer, G.C. 2002. �Therapeutic interaction through metaphor: An
interactive approach to homeopathy�. Semiotica.
141-1/4. pp.1-27. Lakoff,
George. 1990. Women, Fire, and Dangerous Things. Milroy,
Lesley. 1987 (2nd Ed). Language
and Social Networks. Pandit,
P.B.,1972. �Bilingual�s Grammar -Tamil Saurashtri Grammatical Convergence�.
In Rajyashree, K.S. 1986. An
Ethnolinguistic Survey of Dharavi: A Slum in Lexical Organization in
Malayalam-English Bilinguals
Sweety
Joy, Meera Priya.C.S, Aiswarya Anand & Jayashree Shanbal J.S.S. Institute of Speech and Hearing, Ooty Road, Mysore E.
Mail: sweety.slp20@yahoo.com; meeracs_18@yahoo.co.in;
aiiisu_aiiisu@yahoo.co.in; jshanbal@gmail.com Introduction: Haugen, (1953) defined
bilinguals as individuals who are fluent in one language but who �can produce
complete meaningful utterance in the other language�. Since majority of world
population is comprised of bilinguals (De Bot, 1993), a host of studies on
bilinguals is documented in the recent past. The nature of bilingual lexical
organization is an enduring question in bilingual research (Snodgrass, 1984).
An attempt has been made to understand this with different models and
experiments by various researchers. Amongst these experiments, priming
studies have been one widely used method to understand processing
organization. Relationship between lexical organization of a bilingual
semantic, translation priming paradigm and picture naming tasks can be used
to evaluate lexical decision in bilinguals. Studies conducted till date, have
been mostly in alphabetic languages like English, which falls into the Latin
language family. Indian languages, on the other hand are considered syllabic
or semi-syllabic languages. Studies investigating priming patterns in Indian
English bilinguals (like Malayalam-English) are thus necessary to study the
nature of language processing and its representation in syllabic or
semi-syllabic (non-alphabetic languages). Aims of the study: Present study was designed with
the following objectives, 1. To investigate cross language priming (translation
and semantic) in normal M-E bilinguals adults at 250 millisecond stimulus
onset asynchrony (SOA), using a stimulus set designed for automatic
processing. a) prime presented in Malayalam , (L1) and the
target in English (L2) ; L1-L2 condition b) prime is presented in English (L2) and the
target in Malayalam ( L1);L2-L1 condition 2. To investigate cognitive flexibility using
picture naming task and thereby check the sensitivity of word association (Potter,1984) and
concept mediation model (Potter 1984),by comparing the reaction time taken
for picture naming task and L1-L2 translation task. Method: Subjects: Eighteen adults in the age
range of 17- 30 years, with Malayalam as mother tongue and English as second language,
participated in the study. Educational qualification with a minimum of 12
years of formal education was considered for subject selection. Subjects were
categorized as bilinguals or monolinguals based on ISLPR (International
Speech Language proficiency rating scale) (Wiley & Ingram, 1985) scores. Test Stimuli List 1: Translation equivalent word
pairs, semantically related word pairs, semantically unrelated word pair
forms the stimulus material for lexical decision task. Prime words would be
given in Malayalam and target was in English. List 2: Prime words would be given in
English and the target was in Malayalam. List 3: 10 categories of nouns with
each set of five pictures in series having four pictures from one lexical
category. A total of fifty pictures were chosen for the study. Instrument A Compaq 2374 model laptop with
DMDX software (Forster & Forster, 1999) was used for the experiment. Procedure Task 1: The experiments comprised of
two language conditions: Malayalam � English and English to Malayalam,
consisting of 3 blocks the stimulus set in each block containing 63 word
targets ( 21 translation equivalent (TE, ) 21 related( R ) word , 21
unrelated (UR) prime � target word pairs. The final list consisted of 126
word targets in both the language order. Prior to each experimental session
(i.e. for each individual subjects), the order of items with in each of this
block randomized and then the order of three blocks was randomized so as to
decrease the likelihood of extraneous serial effects such as practice or
fatigue. Stimulus presentation was controlled by DMDX software (Forster &
Forster, 1999). Subjects responded by pressing the key �1� (for a �yes�
response) and key �0� (for a �no� response) on the key board. Reaction times
(RTs) were recorded to the nearest millisecond and stored in the computer. Task 2: Series of pictures were shown
on the computer screen .Subjects was instructed to name the picture as early
as possible in their native language. The verbal responses were recorded with
the help of a microphone connected to a computer. Recording and Scoring The reaction times in
milliseconds of all the critical targets were automatically recorded in
Microsoft excel by the software further data was analyzed using statistical
package for social science (SPSS-10.0) version software. Results and Discussion The results will be discussed
in light of the differences in lexical organization in bilinguals proposed
for bilinguals in the western population in comparison to the Indian population
following a different script structure. REFERENCE: Colthart., & Karanth,P.,(1984).Analysis of the
acquired disorders of reading in Kannada. Journal of All India Institute
of Speech and Hearing, 15, 65-71. De Bot, K. (1993). A Bilingual production model: Levelt�s
speaking model adapted. Applied Linguistics, 13, 1-24 Forster,J., & Forster,k.(1999).http://
www.u.arizona.edu/~ kforster /dmdx., retieved on 12/9/2008. Haugen, E. (1953). The analysis of linguistic borrowings. Language, 26,210-231 Potter, M.C., So, K.F., Von Eckhart, B., & Feldman,
L.B. (1984). Lexical and conceptual representation in beginning and proficient bilinguals. Journal of Verbal Learning and Verbal Behavior, 23, 23-38. Wylie., & Ingram, E.D.,
(1985). How native like? Measuring language proficiency in bilinguals. Journal of Applied Linguistics, XI
(2), 47-64 Temporality in Bengali: A
Syntacto-Semantic Framework
Samir
Karmakar Department of Humanities and Social Sciences, IIT, Kanpur E.
Mail: samirk@iitk.ac.in The syntactic pattern of Bengali verb morphology shows the
following structure: 1. ������������������� V-aspect-tensei-personi
Here, I would show how the syntactic structure corresponds
to the temporally significant semantic aspects, such as temporal ordering, viewpoints,
lexical aspect, and argument structure, in Bengali. Following Reichenbach (1947), the information about the
temporal order could be captured in terms of speech time (= S), and reference
time (= R), whereas the relation between reference time and event time (= E) gives an idea about
the viewpoints. These two relations are popularly known as first and second referencing, respectively. On the other hand, the
information of lexical aspect is a consequence of aktionsarten.
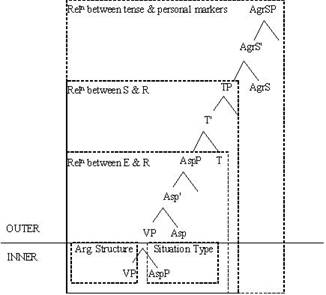
Fig 1: Syntacto-Semantic Frame of Temporality in Bengali The information pertinent to temporal order and viewpoint constitutes
the outer layer of the frame; whereas aktionsarten
along with the argument structure
constitutes the inner layer of the frame (Verkuyl 1989, 1993). Inner layer of
the frame represents lexical aspect in terms of duration, and telic
features. Outer layer is mainly concerned with (i) the relation between
speech time and reference time, in terms of precedence and overlap,
and (ii) the relation between reference time and event time, to construct
either perfective or imperfective �viewpoints. Arche (2006) has shown how these
semantic notions could be incorporated into a syntactic framework, simply by
assuming tense and aspect to be dyadic
predicate relations. The framework, which I have outlined here differs in
certain respects from that of Arche�s one, mainly due to the language
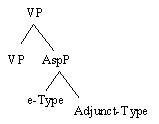
specific peculiarities of Bengali. The adverbial adjunct modifies the lexical aspect of a
sentence either as state, or process, or event, thus coercing the verb semantics. Such modification is
proposed to be dealt with in the inner layer of the frame, under the node of
aspect.
����������������������� The sentence from Bengali above
has two readings: (i) the act of singing was accomplished in fifteen minutes (accomplishment); and, (ii) the act of
singing was started in fifteen minutes
(inception). However, in case of
(2b), no such problem arises. It simply means, the act singing had been
performed for fifteen minutes.
����������������������� As a consequence the inner layer of aspect needs to be
further decomposed in the following way:
Fig 2: Further Specification of VP-internal Aspectualities Integration of syntax and semantics is crucial, since it
shows how the semantics of tense, aspect (both grammatical and lexical), and
the adjunct interact with each other, while construing the temporal
interpretation of a sentence that takes into cognizance the discourse level
contextualities. References: Arche, M.J. (2006). Individuals in
Time: Tense, Aspect and the Individual/Stage Distinction, Amsterdam: John
Benjamin Publishing Co. Verkuyl, H. (1989). Aspectual
Classes and Aspectual Composition. Linguistics and Philosophy, Vol. 12,
39-94. Verkuyl, H (1993). The Theory of
Aspectuality: The Interaction between Temporal and Atemporal Structures,
Cambridge: Cambridge University Press. Reichenbach, H. (1947). Elements
of Symbolic Logic. New York: The Free Press. Gilchrist's 'A Grammar of
Hindoostanee Language': Some Colonial and Contemporary Imprints
Santosh
Kumar Deptt. Of Linguistics, University of Delhi, Delhi E.
Mail: santoshk.du@gmail.com The contextual and textual analysis of a piece of grammar has always
been an interesting and challenging area of inquiry. This paper examines
Gilchrist�s A Grammar of Hindoostanee
Language with the aim to show that often grammar-writing can be seen to
provide a framework to �keep in circulation� the imperialist project
(Bhattacharya 2004) The
history of writing grammars shows that grammars are written for specific linguistic reasons such as to provide a principled
description of a particular language; to be a basis for
language pedagogy; to compare one grammar with another for typological,
historical, and aerial characteristics or for pedagogically oriented
contrastive analysis, and to test linguistic theories (Ferguson, 1978).
However, there are some non-linguistic reasons such as culture, religion,
ecology, aesthetics, pragmatism, etc. that influence the practice of writing grammar, wittingly or otherwise
(Scharfe, 1977). The latter perspective provides a significant site for raising questions of
representation, power and historicity. John
Borthwick Gilchrist�s �A Grammar of Hindoostanee language or part third of volume
first of a system of Hindoostanee
philology� (Calcutta, Chronicle Press, 1796) is one of the earliest
grammars written on the Hindustani language. This well-studied text can
however be seen as representative of the colonial language policies put in
place by the British to serve their needs in addition to its being
representative of the British attitudes towards Indian vernaculars in general
and Hindustani in particular.
Notwithstanding problematic such as these in a purportedly scientific
activity like grammar writing, this paper also presents comparative evidence
to show that the contemporary mindset is not without blemish when it comes to
pursuing an imperialist agenda through academic writing. Reference: Bhattacharya, Tanmoy. 2004. Hand me my slippers and other such phrases as a part of grammar:
Pettigrew�s Tangkhul Naga Grammar. Paper presented at the 26th
AICL Meeting, NEHU. Bhatia, Tej K. 1987. A History of the Hindi Grammatical
Tradition: Hindi-Hindustani Grammar, Grammarians, History and Problems.
Leiden, The Netherlands: E. J. Brill. Ferguson, C.A. 1978.� Multilingualism
as object of linguistic description. In Kachru, Braj B. ed.
Linguistics in the Seventies: Directions and Prospects. Department of Linguistics,
Urbana, University of Illinois. Gilchrist, J.B. 1796. A Grammar of the Hindoostanee language or
Part third of volume first of a system of Hindoostanee philology. Calcutta:
Chronicle Press. Scharfe, Hartmut, 1977. Grammatical Literature. Wiesbaden: Otto Harrassowitz. Suleri, S. 1992. The Rhetoric of English India. Chicago: The University of Chicago
Press. The Biolinguistic Diversity Index of India
Ritesh
Kumar Centre for Linguistics, SLL&CS, Jawaharlal Nehru
University, New Delhi E.
Mail: riteshkrjnu@gmail.com In recent times there has grown a strong hypothesis which asserts
that the biological, cultural and linguistic diversity of a country or a
region are positively correlated. These three diversities are together termed
as 'biocultural diversity'. Thus, biocultural diversity unifies the diversity
of life in all of its manifestations: biological, cultural, and linguistic.
These are interrelated and have coevolved within a complex socio-ecological
adaptive system. There are three basic assumptions underlying the concept of
biocultural diversity:
The cumulative effect of all these local interlinkages,
interdependencies and interaction between the humans and the environment
implies that at the global level, biodiversity and cultural diversity are
also interlinked and interdependent. Thus, it has significant implications
for the conservation of both the diversities. Recent global cross-mappings of
the distributions of biodiversity and linguistic diversity (taken as a proxy
for cultural diversity) have revealed significant geographic overlaps between
the two diversities, especially in the tropics. Moreover, they have shown a
strong coincidence between biologically and linguistically megadiverse
countries. It has been noted that generally the social factors
combine with the geographic and climatic factors leading to a higher or lower
diversity. For example, geography and climate of a particular area affects
its carrying capacity and access to resources for human use. Ease of access
to abundant resources seems to favour localized boundary formation and
diversification of larger numbers of small human societies and languages.
Where resources are scarce, the necessity to have access to a larger
territory to meet subsistence needs favours smaller numbers of widely
distributed populations and languages. The development of complex societies
and large-scale economies, which tend to spread and expand beyond their
borders, also correlates with a lowering of both linguistic and biological
diversity. Moreover, there is a significant overlap between the location of
threatened ecosystems and threatened languages. On the other hand, low
population density, at least in tropical areas, seems to correlate positively
with high biocultural diversity. It has been argued that similar forces are currently
posing a danger to both the linguistic and the biological diversity on Earth.
And the preservation of both the diversities is extremely necessary for
similar reasons. While biodiversity provides us the resources of Nature on
which we can fall back for our sustenance and better living, linguistic
diversity gives us the vast pool of knowledge from which we can draw upon to
make our life better. The knowledge of biodiversity and how it can be used is
encoded in thousands of so-called tribal, backward and insignificant languages.
Once these languages are lost, we lose this vast pool of knowledge in the
form of traditional knowledge, from which we could have learnt a lot. One of the biggest obstacles in this nascent field of biocultural
(or, biolinguistic, for my purpose) diversity is the lack of a proper
methodology and a good database. Since these diversities are best expressed
in terms of figures and numbers, we need to have some kind of mathematical
and statistical index for representing this integrated notion of
biolinguistic diversity and then by studying the fluctuations in this index
over a period of time, we can gauge the extent to which these diversities are
under threat. Obviously after that the qualitative analysis regarding the
causes and the� possible solutions to
this threat is necessary. But in order to get the qualitative analysis to the
point and exact, we need to know the exact proportion and extent of the
threat. Harmon and Loh calculated the 'Index of Biocultural
Diversity' (IBCD) at the global-level (they calculated the index for each
country and then compared them). However the problem with their methodology
was that it could not be used for smaller areas or intra-country calculation
of index. So it required some modification. In this paper I have calculated
the IBLD (Index of Biolinguistic Diversity) of India using a similar
methodology. However I have introduced some modifications. Instead of taking
the politically divided states as the reference point for comparison, I have
taken the eco-regions of India as the reference point. I think this will give
a better idea of the diversities because these eco-regions are divided by WWF
on the basis of the distribution of�
biological species. Thus they are scientifically constructed for
studying biodiversity itself and so�
more appropriate for my study. Besides this, the availability of data
is another reason (a kind of bonus) for selecting eco-regions as the
reference point, instead of the political states. Moreover, I have also
calculated the Spearman's rank correlation coefficient between the ranks of
the eco-regions on the basis of biodiversity and linguistic diversity so as
see whether these are correlated at the intra-country level (in India, in
particular). And this comes out to be quite high. Thus the correlation
between biodiversity and linguistic diversity is mathematically established,
at least, for India. The presence of a positive correlation between
biodiversity and linguistic diversity at the intra-country level conclusively
establishes the fact that these two are indeed correlated. The calculation
also establishes the north-eastern and gangetic valley region as the most
biodiverse as well as linguistically most diverse regions of the country.
Finally the fact that geographic factors and climate affect the development
of both kinds of diversities is also established. Gangetic Valley and
North-East of India are the most productive and resourceful areas of India
(as is shown by their extreme biodiversity) and also linguistically most
diverse. Thus the hypothesis that abundance of resources favours both
biological and linguistic diversity also holds true in case of India. Now that the preliminary calculations are carried out and
basic facts are established, further work is required to calculate the change
in these diversities over a time-period and see if there is any correlation
related to the factors and the rate of the change. Terralingua is working on
a database for the time-series data of linguistic diversity; for biodiversity
it is already available. Once the database is complete, further insights into
the field can be obtained. Moreover, the conclusions above are not
established unanimously; there are some glaring exceptions which need to be
explained and for that we need better database; a more refined methodology;
and perhaps, a better hypothesis. References: 1.
Carder,
Maurice. A Word of Difference, from
�Resurgence Magazine� 2008, 250. 2.
Gupta,
S.C. and V.K. Kapoor (2003). Fundamentals
of Mathematical Statistics. Sultan �Chand & Sons. 3.
Loh,
Jonathan and David Harmon. A global
index of biocultural diversity, from ���
�Ecological Indicators�, 2005. 4.
Maffi,
Luisa. Language: A Resource for Nature,
from �The UNESCO Journal on the �Environment and National Resources Research�
1998, 34(4). 5.
Maffi,
Luisa. Linguistic, Cultural and
Biological Diversity, from �Annual Review of �Anthropology� 2005. 6.
Maffi,
Luisa. Biocultural Diversity and
Sustainability �The Sage Handbook of ��
Environment and Society� 2007. 7.
Maffi,
Luisa. Cultural Vitality, from
�Resurgence Magazine� 2008, 250. 8. Skutnabb-Kangas, Tove (2008). Linguistic genocide in Education or Worldwide �Diversity and Human Rights. Orient Longman. Bhojpuri waalaa
Shailendra
Kumar & Neha Vashistha Dept. of Linguistics, BHU, Varanasi E.
Mail: shail.linguistics@gmail.com In many north Indian languages, waalaa plays a very
diverse functional roles. In major languages such as Hindi (Bhatia 2008,
Sharma 1958, Shapiro 1989) the topic has been studied in detail. Although, waalaa
seems to have more or less similar roles in many of the languages in
which it is used and can be categorized on similar ground. However, the uses
of waalaa in Bhojpuri deserve a separate discussion. In this paper, we
attempt to do this. First of all we examine the various uses of waalaa in
Bhojpuri. For this we rely on my own native language intuition and also
collect relevant data from friends and other speakers. Secondly, we attempt
to make a categorization of waalaa according to its functional roles.
Some illustrative examples are presented below: (1) a. tohaar waalaa kaam kab hoi? (sabhane ka to kaam
kabka hogawaa baa). your CF work when happen-will �When will YOUR work happen?� (all the others have
finished their work long time back) b. phon-waalaa pEsaa kahaaN baa? phone-for/from money where is �Where is the money meant for/that came from phone? In the first use (1a), waalaa is used as a
contrastive focus (CF) marker as it can be contrasted with the work assigned
to others (this is shown in the bracketed part of the example). In (1b), on the other hand, the use of waalaa can have many
interpretations as is shown in the English translation of the sentence. In this paper, we examine the various uses of waalaa in
Bhojpuri and categorize them according to their various functions. We also
examine the constructions that do not allow the uses of waalaa in
certain contexts and the constraints on them. References: Bhatia, T. (2008). Colloquial Hindi: The Complete Course for
Beginners: Routledge Shapiro, M. (1989). The Primer of Standard Hindi.
Motilal Banarasidas. Delhi. Sharma, A. (1958). A Basic Grammar of Modern Hindi.
CHD, Govt. of India. Gitanjali�: A Study in
Lyrical Patterns (Syntax, Diction & Rhythm)
Kusum Govt. College Boys, Civil Line, Ludhiana (Punjab) E.
Mail: kusumgopal@yahoo.co.in Rabindranath Tagore said that each language possesses its
own rich resources and energies. Although originally written in Bengali, the
English translations of �Gitanjali� read like original poems. The language
used by Tagore as translator is highly emotive, highly charged with the
energies of the heart. The French symbolist poet Mallarme said: �Poetry is written
with words, not ideas�. The words used by the poet are remarkable for their
sound, sense and suggestion. He is a quite aware of the importance of the
Liquid Consonants � /l/m/n and/s and/j/. Now, I ask, has the time come at last, when I may go in and see thy
face and offer thee my silent
salutation? Since the songs in Gitanjali are devotional and the
divinely inspired, patriotic and have nationalistic strains, the tone,
rhythm, pitch, cadence are have inner rhyming. The poems don�t have any
regular proper meter. They are proper free but still they have proper
discipline. This is due to the fact that the poet creates �form within form�.
They have a openness of Alexander Pushkin�s poetry, e.g. IF thou speakest not I will fill
my heart With thy silence and endure it. I will keep still & wait like
the night. Into that heaven of freedom, my Father, let my country awake. The present paper proposes to
establish how in early 20th Century GURUDEV TAGORE proved that translation of poetry
is the second most important thing literature. The paper will also explore
the linguistic structures used for poetic purposes and creative function.
Poetry for Tagore was an act of faith. Translation, transcends, the barriers
of language, cultures, continents & communities. Case marking in Asamiya in
comparison with Bangla
Bornini
Lahiri Centre for Linguistics, SLL&CS, Jawaharlal Nehru
University, New Delhi E.
Mail: lahiri.bornini@gmail.com ����������� The present paper focuses on case
marking in animate and inanimate objects of Asamiya in comparison with
Bangla. These two outer Indo-Aryan languages share many features. If one
looks at the case marking of the two then it can be seen that they share most
of the cases though they are realized differently through affixation and
postpositions. The reason behind their similar case marking feature lies
behind the fact that both belong to eastern group of Indo-Aryan languages and
are descendent of Magadhi Prakrit. ���������������� Both the languages
differentiate between animate and inanimate objects through their case
marking features. In both the languages the accusative (ACC) case marking of
an inanimate object is dropped. eg1 (a):����������� ram���� hori-k������������� dekhile����������������������������������� (Asamiya) ����������������������� Ram���� hari-ACC������� ���
saw������������� ����������������������� (word-to-word) ����������������������������������� Ram saw Hari������������������������������������������������ (free
translation) eg1 (b):����������� ram���� am-to������������� dekhile����������������������������������� (Asamiya) ����������������������� Ram���� mango-CLA��� ��
saw�������������������������������������� (word-to-word) ����������������������������������� Ram saw the mango��������������������������������������� (free
translation) In Asamiya accusative case
marking does not come with an inanimate object but in Bangla if it is not
dropped then the inanimate object gives the reading of an animate object
which in most of the instances is ungrammatical like Asamiya but not always
as can be seen in example-2 (c). eg2 (a):����������� ram���� hori-ke����������� dekhlo ����������������������������������� (Bangla) ����������������������� ram����� hari-ACC������� saw����������������������������������������� (word-to-word) ����������������������������������� Ram saw Hari������������������������������������������������ (free
translation) eg2 (b)������������ ram���� am-ta������������� dekhlo ����������������������������������� (Bangla) ����������������������� ram����� mango-CLA��� saw����������������������������������������� (word-to-word) ����������������������������������� Ram saw the mango��������������������������������������� (free
translation) eg2 (c): ���������� ram���� boStu-ti-ke���������������� dekh-lo���������������������� (Bangla) ����������������������� ram����� thing-CLAS-ACC����� see-1st PER SING������ (word-to-word) ����������������������������������� Ram saw the thing(animate). ������������������������ (free translation) ����������� In example -2 (c) accusative case marking is used with
an inanimate object but the reading is that of an animate. Here some person
or some animal has been degraded to an inanimate object and the sentence
reveals that the speaker has purposely done so. But it should be noted that
the object here takes accusative case marking after taking the classifier
/-ti/. Without any classifier like /-ti/, /-ta/, /-gulo/, an inanimate object
can never take an accusative case marking, in Bangla. The
distinction between animate an inanimate is also maintained through locative
(LOC) case marking in Bangla and instrumental (INST) case marking in both the
languages. Locative case marking when used with animate in Bangla doesn�t
give locative meaning but can be used for generating many other meanings,
including that of generic, coupled reciprocals and accusative-dative. eg3 (a): ���������� kukur � e�������� kamre��� dae. ����������� ����������������������� (Bangla) ��������� ������������� Dog�� - LOC������
bite�������� give���������� ������������ ���������� (word-to-word) �������������������� �������������� �Dogs bite������������������������������������������������������� (free
translation) eg3 (b): ���������� dui������ bondhu-te������ jhogra������������������������������������ (Bangla) ����������������������� two����� friend-LOC���� quarrel������������������������������������ (word-to-word)���������� ����������������������� There a dispute between the two friends.������������������ (free translation) eg3 (c):����������� o��������� ama-e/-ke������������������� bollo��������������������������� (Bangla) ����������������������� he/she� I-LOC/-ACC������������� said����������������������������� (word-to-word) ����������������������������������� He/she told� me.��������������������������������������������� (free
translation) �Asamiya uses two different case markers for
instrumental case depending on whether the object is animate or inanimate.
Whereas Bangla uses a postposition for instrumental case but when the object
is animate then the postposition is preceded by the accusative case marking. eg4 (a):����������� jharu�� dije����� jhat���� deao��������������������������������������� (Bangla) ����������������������� broom� INST�� sweep�
����������� give���������������������������������������� (free
translation) ����������������������� Get it swept by the broom.���������������������������������������� (word-to-word) eg4 (b):����������� dai-ke������������� dije����� jhat���� deao��������������������������� (Bangla) ����������������������� maid-ACC����� INST�� sweep�
����������� give���������������������������� (free
translation) ����������������������� Get it swept by the maidservant.������������������������������� (word-to-word) ����������� This paper is a trial to focus on the problem of different
types of case marking used in the two languages, depending on whether the
object is animate or inanimate. Both, Asamiya and Bangla perceive differences
between animate and inanimate objects through various case markings. Though
both the languages follow a similar pattern to differentiate between animate
and inanimate objects through case marking yet there lie differences like
Asamiya uses two different markers for animate and inanimate objects in
instrumental case while Bangla uses the same with an additional accusative
marking for the animates. In this paper I have tried to study various case
markings of Asamiya and Bangla which create difference between animates and
inanimates and have also looked upon the instances where a particular case
marking differentiates between the two, in one language but not in the other. References: �Abbi A (1994), Semantic universals in Indian
languages .Shimla: Indian Institute of Advanced Study. Blake, B. J. (1994).Case. Cambridge: Cambridge University Press. Dasgupta P (2003)
�Bengali�. The Indo-Aryan languages. edi: Cardona G & Jain D London: Routledge
Publication Goswami S (2003)
�Asamiya�, The Indo-Aryan languages. edi: Cardona G & Jain D London: Routledge
Publication Masica , C.P (1991).The Indo-Aryan
Languages. Cambridge: Cambridge University Press. Masica , C.P (1976). Defining a Linguistic
Area: South Asia. Chicago: University of Chicago Press The Semantics of
Classifiers in some Indian Languages
Bornini
Lahiri, Ritesh Kumar, Sudhanshu Shekhar & Atanu Saha Centre for Linguistics, SLL&CS, Jawaharlal Nehru
University, New Delhi E.
Mail: lahiri.bornini@gmail.com; riteshkrjnu@gmail.com; shekhar921@gmail.com;
atanu.jnu@gmail.com Every language in the world classifies Nouns and nominals
in one way or the other. Predominantly people categorise the world through
their language in terms of universal semantic parameters involving humanness,
animacy, sex, shape, form, consistency, and functional properties. Basically
there are two kinds of noun classification systems found in the languages of
the world-- noun class system and classifier system. Both these systems
classify nouns on the semantic basis. But they differ morphosyntactically as
well as on the basis of preferred semantic features. Noun class systems are
those in which the classification of Noun is not represented morphologically;
rather the different classes of Nouns are shown by the grammatical agreement
with verb. For example, Hindi is a noun class system, where every Noun is
kept in either of the two classes-- Masculine and Feminine. There is no
universal morphological marking which is given to Nouns belonging to one
class; but obviously there is agreement with verb. While in Hindi, Nouns are
classified just into two classes, it can go up to 10 as in some Bantu
languages and even to several dozen as in some South American languages. The
classifier languages differ from the class languages on the account of being
morphologically represented. Nouns or numerals are marked by the classifier
they take. While in Noun classifier languages the classifier comes with the
Noun, in Numeral classifier languages, it is represented on the numeral (and
so it comes only in the cases where noun comes with the numeral). All the
Tibeto-Burman languages, Eastern Indo-Aryan, some Munda languages, Khasi and
a few Dravidian languages in India are classifier languages. We carried out a typological survey regarding the
occurrence of classifiers (both numeral and noun classifiers) in 17 languages
across 4 language families of India. We looked at 6 languages from
Indo-Aryan�Assamiya, Bangla, Magahi, Maithili, Bhojpuri and Oriya; 2
languages from Austroasiatic�Santhali, and Khasi; 3 languages from Dravidian
family�Telugu, Tamil, and Kurux; and 6 languages from Tibeto-Burman
family�Nyishi, Tagin, Galo, Ao-Naga, Meithei, and Mizo. All these language
have classifiers in some form although their number varies from 2 (in
Indo-Aryan language like Magahi) to around 80 (in Tibeto-Burman languages
like Tagin). Looking at the overall picture, it can be concluded that numeral
classifiers are more predominant in these languages when compared to noun
classifiers. Except the languages belonging to Tibeto-Burman family (and some
languages from Indo-Aryan), all languages have only numeral classifiers. In this paper we have enumerated and described the
findings of this survey. We have chiefly concentrated on the semantics of the
classifier systems since the choice of the classifier generally depends on
the semantics of the head noun. In almost all the languages, animacy forms
one of the basic criteria for the classification on nouns in language. In
Tibeto-Burman languages the classification system is very extensive and there
is huge number of classifiers, particularly numeral classifiers. Moreover, in
languages like Tagin, Galo and Nyishi, there is a system of reduplicating the
first syllable of the noun and the reduplicated syllable is attached with the
numeral, which acts as the classifier. This is done for almost all the nouns
which do not occur with any of the commonly-used classifiers. These
classifiers are, thus, used with only one noun. However there are other
classifiers also which are guided by such semantic properties of the nouns as
shape, size, material of the object, animacy, etc. These languages have only
numeral classifiers. However some other Tibeto-Burman languages like Ao-Naga,
Meithei and Mizo have both noun and numeral classifiers. When the noun occurs
without a numeral, the classifier follows the noun but when there is a
numeral, the order becomes numeral-classifier-noun. We have studied only two Austroasiatic languages
(the study is still under way and we are trying to get data for other
languages like Ho, Mundari, Sora, Kharia and Panar). Out of these two, Khasi
has a very extensive classifier system, particularly numeral classifier
system and resembles its surrounding Tibeto-Burman languages. But in Santhali
the system of numeral classifier is very limited and complex. The classifier
is not used with every numeral (and obviously not with every noun) and quite
a complex system emerges out. In case of Dravidian languages also the system
is not very elaborate and quite complex. In case of Indo-Aryan languages the system, again,
differs from language to language. Assamiya has the most productive and
extensive system of both the noun and numeral classifiers. Bangla, Oriya and
Maithili do not have such an extensive system as Assamiya but still the use
of classifiers is quite significant when compared to other Indo-Aryan
languages. However in case of Bhojpuri and Magahi the system becomes very
limited with both having just two classifiers each. In Magahi the distinction
seems to be of human and non-human; but in Bhojpuri even that distinction is
blurred. And for that matter even in Magahi the distinction is not maintained
by all the speakers and in conscious speech everyone agrees that one can be
substituted for the other without producing any kind of strict
ungrammaticality. Despite these differences between the distribution
and occurrence of classifiers in different languages, it emerges that the
semantic basis of the classification is similar. Typical semantic parameters
are animacy, humanness, and physical properties such as dimensionality, and
shape. We have also noted the cases of specific classifiers for nouns which
may be considered culturally important, e.g., canoe, house. Moreover in
several languages one noun can take several classifiers depending on which
feature or characteristic of the noun the speaker is trying to point out or
emphasize. References: 1.
Aikhenvald, A Y (2000). Classifiers: a typology of noun categorization devices. Oxford:
Oxford University Press. 2.
Aikhenvald, A Y (2006). Classifiers and Noun Classes: Semantics, from �Encyclopedia of Language and Linguistics� eds Keith
Brown (editor-in-chief), Anne Anderson, Laurie Bauer, Margie Burns, Jim
Miller and Graeme Hirst (Elsevier Pvt. Ltd., 2006). 3.
Kidwai, Ayesha and Joyshree Sutradhar (2008). The Morpho-Syntax
of Classifiers in (three) Indian Languages: The Mass/Count Distinction, presented in CGIML-08 at IIIT-H. Word Retrieval Abilities in
Bilingual Geriatrics
Ramya Maitreyee*,
Ridhima Batra*, Mr. Brajesh Priyadarshi** * II M.Sc. (SLP), All India
Institute of Speech and Hearing, Mysore- 570006. ** Lecturer, Clinical Linguistics,
All India Institute of Speech and Hearing, Mysore- 570006. E-mail:
maitreyee_ramya@yahoo.co.in, canif_ridhima@yahoo.co.in,
brajeshaiish@gmail.com INTRODUCTION Bilingualism is a major fact of life in today�s world.
Weinreich (1953) defined bilingualism as �the alternate use of two languages�
and Haugen (1953) suggested bilingualism began with �the ability to produce
complete and meaningful utterances in the second language�. The term �word retrieval� refers to the processes involved
in mentally identifying and then producing the word or words needed to
express a thought or name an object. Word retrieval relies on the development
of two systems; the
meanings of words are stored in the brain in the Semantic Storage System as a large number of connections and
systems of connections among nerve cells which correspond to word
associations. On the other hand, the sounds in a word and their organization
are stored in the phonologic storage system of the brain. Thus there are two
storage systems and they need to work in harmony in order to support fast,
fluent, and effortless retrieval of words. Word problems occur when a person tries but fails to
produce a word that is known to be part of his receptive vocabulary. Word
retrieval problems are indicated by the �tip-of-the-tongue� difficulties, by
frustration at not being able to say what one wants, by frequent use of
nonspecific words or circumlocutions or by frank admission of retrieval
difficulty. Word retrieval problems might result in slow but accurate
retrieval, slow and inaccurate retrieval, fast but inaccurate retrieval, or
total retrieval failure. Elderly
individuals frequently report difficulties in word retrieval. Such failures in lexical
retrieval have been demonstrated in both cross sectional and longitudinal
studies (e.g. Au et al., 1995) and include not only the findings of referents
to a definition but also of verbs and proper names, beginning as early as the
late 50s and increasing as the individual reaches the 70s. In a study
conducted by Hough (2007), he found that overall, 28% of the adults exhibited
abnormal word finding standard scores on the Test of Adult Word Finding (German, D. J., 1990). Till date majority of the
studies have focused on word retrieval abilities in monolingual geriatrics,
but is the same mechanism involved even in a bilingual yet needs to be
confirmed. How is it possible for a bilingual to keep her two languages separate
during language production, and therefore translate the preverbal message
into words of only one lexicon? This is an important issue, because failure
to achieve lexical selection in the desired language may have disastrous
effect on communication. AIM: To test the word retrieval abilities in bilingual
geriatrics. OBJECTIVES 1)
To examine the difference, if any, in the word retrieval abilities of
bilingual geriatrics in both their first and second language on picture
confrontation naming task. 2)
To examine if there is an effect of grammatical class on word retrieval
abilities. METHOD Participants: A total of 25 adult bilingual participants were included
in the present study. All the participants were native
speakers of Kannada (L1) and had acquired
English as their second language (L2) for
academic and communicative purposes and were highly proficient users of the
language. All subjects were normal, with no
past / present history of any neurological, psychological problems and or
sensory deficits. Ethical
concerns: Participants were selected by
ethical procedures. They were explained the purpose and procedures of the
study, and an informed verbal and/or written consent was taken. Age
range: 60 years and above. Materials �
Stimuli
used: A non-standardized list of proper
and common nouns and verbs in picture form served as the test stimuli. The 45
picture stimuli consisted of: � 15 proper nouns � 15 common nouns � 15 verbs �
Selection
of stimuli: The words ranging from simple to complex
levels were chosen for the study. �
Recording
of stimuli: The picture stimuli were
collected and transformed into the DMDX software (Forster & Forster,
1999). All the 45 stimuli were randomized and each item was presented twice
and the average response for each item was considered. Procedure:
The International Second Language
Proficiency Rating (ISLPR) (Ingram, 1985) was
administered and all the participants having vocational proficiency in
English were chosen for the present study. The final test material was
presented in an individual set-up in a quiet environment using the DMDX
software run on a laptop. Before the administration of the final stimuli 3
test trials were given to each of the participants. Task: The participants were asked to look carefully at the
pictures and were asked to name them in Kannada (L1). The same picture
stimuli were used again for checking word retrieval in the second language
(L2) i.e. English in the current study. For retrieval of verb forms the
participants were asked to answer to the question �what is the person in the
picture doing?� The responses were audio recorded using a microphone
connected to the laptop. Scoring
and coding: The responses were measured for
accuracy and reaction times (RT) (in ms). A score of 1 was coded as correct/
accurate and a score of �0� was coded as wrong/inaccurate. RESULTS: Both quantitative and qualitative analysis of the data was
done and the results indicated a decline in word retrieval abilities with old
age. It was also seen that the word retrieval abilities for common and proper
nouns was more impaired than the verbs. Statistical analysis and the results
will be discussed in detail in the paper. REFERENCES: German, D. J. (1990). Test of
Adolescent / Adult Word Finding. Allen, TX: DLM teaching Resources. Haugen, E.� (1953). The Norwegian Language in America.
Cambridge: Cambridge University Press. Hough,M.S.(2007).Incidence of word �finding difficulties
in normal aging. Folia Phoniatrica
Logopaedics,59(1). Ingram, E.D. (1985). How native like? Measuring Language
Proficiency in bilinguals. Indian
Journal of Applied Linguistics, 11, 47-64. Weinrich, U. (1953).� Languages in contact. New York:
Linguistics Circle of New York. Implementation of Transfer Grammar in Telugu Hindi Machine
Translation System
Christopher
Mala IIIT-Hyderabad, Gachibowli, Hyderabad E.Mail: christopher.mpg08@reserach.iiit.ac.in,
guraohyd@yahoo.com This paper describes experiments
on Transformation of grammar from one language to another while translating
text through machine. As it is know that every language has its own phenomena
and its own way of representation. But while translating from one language to
another its very important to retrieve theses language phenomenal information
of target language from source language, which may not be there in the source
language. These language dependent phenomena can be seen when we are
translating languages of cross language family's. In this paper we have tried
to explain how grammar is transferred from Telugu (Dravidian language family)
to Hindi (Indo-Aryan family). There may be many criteria� that has to be taken in consideration� while transferring the grammar, like, 1)
Adding of language Copula and other language specific data 2) Deletion of grammar
that is not required in the target language�
3) Modification of the source language grammar according to target
language 4) Smoothing of the target language grammar. In this paper it
has also explained Transfer Grammar engine which is of language independent
and can be used by giving rules to it.�
This engine takes input in Shakti Standard format and give output in
Shakti Standard format. This� study is
used in Indian Language -Indian Language Machine Translation (IL-ILMT) system
which is funded by Govt. of India ( Ministry of Information Technology) at
CALTS lab in University of Hyderabad under guidance of Prof. G. Uma Maheshwar
Rao. Automatic Extraction and Incorporation of Purpose Data
into Purposenet
P.
Kiran Mayee, Rajeev Sangal & Soma Paul International Institute of Information Technology,
Gachibowli, Hyderabad-500032 E.
Mail: advalakiranmayee@gmail.com PurposeNet is
a knowledge base of objects and actions in which the knowledge is organized
around purpose. Such knowledge also connects with language � namely, verbs
for related actions. It can be used with an embedded reasoner, resulting in
an effective system for QA, topic-listing, summarization and other tasks.
However, extracting PurposeNet related data manually is time consuming,
labour-intensive, and expensive. This paper describes a framework for
automatic purpose data extraction, given a corpus. It identifies a set of
lexico-syntactic patterns that are easily recognizable, that occur frequently
and across text genre boundaries, and that indisputably indicate the lexical
relation of purpose data. It also deals with the subsequent automatic
incorporation of this data into the PurposeNet resource. The results are used
to augment and critique the structure of a large hand-built resource. The
extent of success, in terms of richness of the resource, achieved in the
process is also discussed. Data Three sets of data were used for our experiments. The
first set was the English corpus obtained from wordnet containing an artifact
file with 11,469 artifact descriptions. This was used for artifact
identification in Sentences. The second set was a corpus obtained from IIIT ,
Hyderabad with 1,32,321 sentences. The corpus was insufficient for our
purpose. Therefore, we also used an independent English corpus of 42,163
sentences. The second and the third corpora were used to test the success
rate for extraction. The newly built resource was the input data for
comparison with the hand-built one. References: 1. PurposeNet : An Ontological Resource
Organized Around Purpose - P.
Kiran Mayee, Rajeev Sangal, Soma Paul, Navjyoti Singh - Proceedings of 6th International Conference on Natural
Language Processing '08. 2. Automatic Extraction of Phonetically
Rich Sentences from LargeText Corpus of Indian Languages Karunesh Arora, Sunita Arora, Kapil Verma, S S Agrawal Natural Language Processing Division, Centre for
Development of Advanced Computing, Noida 3. Automatic Scientific Text
Classification Using Local Patterns: KDD CUP 2002 (Task 1) Moustafa M. Ghanem, Yike Guo, Huma Lodhi, Yong Zhang Dep. Of Computing, Imperial College of Science Technology
& Medicine 180 Queens Gate, London SW7 2BZ, UK 4. A Unified Framework Fof
Automatic Metadata Extaction From Electronic Document Asanee Kawtrakul and Chaiyakorn Yingsaeree, Department of Computer Engineering, Kasetsart
University, Bangkok, Thailand 5. Automatic reconstruction of a
bacterial regulatory network using Natural Language Processing Carlos Rodr�guez- Penagos , Heladia Salgado , Irma
Mart�nez-Flores and Julio Collado-Vides Programa de Gen�mica Computacional,
Centro de Ciencias Gen�micas,
Universidad Nacional Aut�noma de M�xico, Apdo. Postal 565-A, Avenida
Universidad, Cuernavaca, Morelos, 62100, Mexico in BMC Bioinformatics 2007,
8:293doi:10.1186/1471-2105-8-293. 6. Automatic layout and
visualization of biclusters Gregory
A Grothaus , Adeel Mufti and TM Murali Department
of Computer Science, 660 McBryde Hall, Virginia Polytechnic Institute and
State University, Blacksburg VA 24061, USA in Algorithms for Molecular
Biology 2006, 1:15doi:10.1186/1748-7188-1-15 7. Narrative Text Classification
for Automatic Key Phrase Extraction in Web Document Corpora Yongzheng Zhang, Nur ZincirHeywood,and Evangelos Milios Faculty of Computer Science, Dalhousie University , 6050
University Ave., Halifax, NS, Canada B3H 1W5 8. Automatic expert identification
using a text categorization technique in knowledge management systems by Kun-Woo Yang, Soon-Young Huh in Expert Systems
with Applications. Vol.34, No.2, February 2008, pp.1445~1455(11) 9. Identify Topics by Position. Lin C-Y and Hovy E., 1997 Proceedings of the 5th
Conference on Applied Natural Language Processing. 10. Automatic Sentiment Analysis in
On-line Text Erik Boiy; Pieter Hens; Koen
Deschacht; Marie-Francine Moens Katholieke
Universiteit Leuven, Tiensestraat 41 B-3000 Leuven, Belgium Proceedings
ELPUB2007 Conference on Electronic Publishing � Vienna, Austria � June 2007 11. Automatic Text Summarization in
Engineering Information Management Jiaming
Zhan, Han Tong Loh1, Ying Liu, and Aixin Sun School of Computer Engineering, Nanyang Technological
University, Singapore 639798 D.H.-L. Goh et al. (Eds.): ICADL 2007, LNCS
4822, pp. 347�350, 2007 � Springer-Verlag Berlin Heidelberg 2007 12. Automatic Acquisition of
Hyponyms from Large Text Corpora Marti
A. Hearst Computer Science Division, 571
EvansHall University of California, Berkeley Berkeley, CA 94720 and Xerox
Palo Alto Research Center in the Proceedings of the Fourteenth International
Conference on Computational Linguistics, Nantes France, July 1992 Developing a Morphological Analyzer for Kashmiri
Nazima
Mehdi, Aadil A. Laway & Feroz Ahmad Lone Department of Linguistics, University of Kashmir,
Hazratbal, Srinagar-190006 E. Mail: nazimamehdi@gmail.com;
aadillawaye@yahoo.com The role of morphology is very significant in the field of
NLP, as seen in applications like MT, IE, IR, Spell Checker, Lexicography,
etc. So, from a serious computational perspective the creation and availability
of a Morphological Analyzer for a language is important. The basic function
of a Morphological Analyzer is taking a word as an input and analyzing its
grammatical features like its root, stem, affixes and so on. Attempts in this
direction have been made at Language Technologies Research Centre IIIT,
Hyderabad (Khan et al, 2005). The present paper uses the above
mentioned article as a starting point and attempts to develop a Morphological
Analyzer for Kashmiri. A morphological analyzer is a computational tool,
which performs automatic morphological analysis and synthesis of word forms
using an electronic dictionary of base forms. A morphological analyzer takes
a word as an input and produces the root and its grammatical features as
output. Words in the input text are first processed by the
morphological analyzer. Its task is to
identify the root, lexical category, and other features of the given word.
The Morphological Analyzer in question will be a paradigm based (as opposed
to Finite-state Machine based Morphological Analyzer). The notion of a
paradigm being closely related to that of inflection, the paradigm of a word
(root) will be the set of all of its forms, organized by their grammatical
features. Many words share paradigms, i.e. more than one word can have same
inflectional behaviour.Consider the�
following examples from Kashmiri like kɔkur( cock) gagur(rat) and ko:tur(pigeon)� can be put in one paradigm as they take
same inflections� for number gender and
case and similarly the words which behave in the same way can be put in this
paradigm. So, the basic idea behind the paper is that if one paradigm can be
identified a common analysis for all the words sharing that paradigm will be
evolved till the whole language is covered. Second Language (L2)
Vocabulary Acquisition in Icelandic Contexts
Nilufer
Misirili Minnesota State University, Mankato, USA E.
Mail: nilufer.misirili@gmail.com Although several studies have
examined second language vocabulary
acquisition through context, how to effectively learn or teach
vocabulary is still unknown. The lack of published research on the use of
vocabulary-learning strategies in Icelandic language learning guided the
researcher to conduct this study. This study examines the use of vocabulary-learning
strategies, specifically within the framework of Schmitt�s (1997) discovery
(understanding strategies) and learning strategies (memory, cognitive,
meta-cognitive, and social strategies), reported by college-level Icelandic
learners. During this study the researcher examined the course and Icelandic
online course. This study investigated the pattern(s) of
vocabulary-learning strategy use and whether learner Germanic language
background (e.g., Norwegian, Swedish, German, or English) or
instruction affects strategy use. For this study, the researcher interviewed
two post PhDs, one graduate student, and four undergraduate college students
attending a Midwestern state university, each with different majors. The
researcher and the course instructor were included as participants among this
group. Data gathering procedures were course observation and a survey on
vocabulary-learning strategies. Both qualitative and quantitative data
analyses were carried out in this study. Originally, there were
three questionnaires and a survey administered to participants; however, it
was found that the data was consistent across all data collection
instruments; therefore, only the survey was analyzed. The survey results
indicated that during the vocabulary-learning process, learners reported a
variety of strategies, but individuals averaged only slightly more than 12 of
20, or about 60% use of the possible strategies questioned. Discovery
strategies were reported as used primarily by experienced learners, while
learning strategies were used most by less experienced learners. Pronominal Binding in
Hindi-Urdu vis-�-vis Bangla
Aparna
Mukherjee Centre for Linguistics, SLL&CS, Jawaharlal Nehru
University, New Delhi E.Mail:aparna.jnu27@gmail.com The paper aims to study the syntactic properties of the
possessive pronominals in Hindi-Urdu and Bangla. Hindi-Urdu unlike Bangla
exhibits a kind of pronominal binding in which the possessive pronominal must
obligatorily obviate from the closest commanding subject antecedent. This
behaviour is not captured by the Principle B of the standard binding theory. Hindi-Urdu:
Possessive and PP-embedded pronominals in Hindi-Urdu must obligatorily
obviate from the closest c-commanding subject antecedent. The embedded
pronominal may be bound by a higher c-commanding object or by a subject
outside its containing clause. However, non-embedded pronominals respect the
Principle B of the standard binding theory that imposes a condition of
referential independence on pronominals in their binding domain, the CFC.
Outside this domain they may freely be used coreferentially. Bangla: Bangla
pronominals behave like English pronominals. The pronominals embedded in DP
and PP constituents can be coindexed with the closest subject or with a
higher c-commanding object or with a subject outside its containing clause.
But the non-embedded ones do not allow such a coreferential use with other
coreferential expressions within a sentence. Sentences with Possessive pronominals: 1. ra:mi ���������� us-ke*ij kəQmr-e �������� me� ���� gə-y-a: (Hindi-Urdu) ���
ram ������������ 3-Gen ������������ room-Obl ������� in ������� go-Past-Mas ���
�Rami went into his*i/j room� 2. rami ����������� o-r/ta-ri/j �������� baſi
���������������� g�-l-o (Bangla) ���
ram ������������ 3N-Gen ��������� room-Loc ������ go-Past-3N ���
�Rami went into hisi/j room� Sentences with Anaphors: 3. ra:mi ���������� əpne i ������������� kəmr-e
����������� me� ���� gə-y-a: (Hindi-Urdu) ���
ram ������������ self-Gen �������� room-Obl ������� in ������� go-Past-Mas ���
�Rami went into hisi room� 4.
rami ����������� nij-eri ������������� baſi ���������������� g�-l-o (Bangla) ��� ram ������������ self-Gen
�������� room-Loc ������ go-Past-3N �� �Rami went into hisi room� In this paper the anti-subject orientation of the
possessive pronominals will be looked at by making a comparision between the
syntactic dependency of the pronominal and the anaphor on the [Spec,TP], the
landing site of the Subject. This means that such expressions are interpreted
in terms of some other expressions instead of assigning value to them. This
is based on the Feature Determinacy Thesis (Reuland, �Anaphora in Language
Design�), which says: Syntactic
binding of pronominal elements (including �anaphors�) in a particular
environment is determined by their morpho-syntactic features and the way
these enter into the syntactic operations available in that environment. This thesis shifts the focus in the investigation of
binding from macro principles such as the canonical binding condition, to the
question of what types of feature clusters allow or enforce the formation of
syntactic dependency under different conditions. This syntactic dependency,
as pointed out by Reuland (2001) is established by Move/Attract and Checking,
and it is forced by checking grammatical features in a checking
configuration. If the features are in a checking configuration, it entails
that the features are subject to deletion or erasure that can be recovered.
This is the Principle of Recoverability of Deletion (PRD). If there is a
violation of PRD then the deletion of interpretable features is blocked. However, binding of third person pronominals cannot be
encoded by the formation of feature chains, as argued by Reuland (2001). The chain
formation would violate the PRD, since different occurrences of a number
feature need not be interpretively equivalent, thus explaining the anti-subject oriented feature of
Poss-pronominals in Hindi-Urdu. Bangla pronominals behave like English pronominals. The
pronominals embedded in DP and PP constituents can be co-indexed with the
closest subject or with a higher c-commanding object or with a subject
outside its containing clause. But the non-embedded ones do not allow such a
co-referential use with other co-referential expressions within a sentence.
The Bangla DP structure as proposed by Bhattacharya (1998) has functional
projections for Dem. According to this proposal the Poss is generated at a
much lower shell and moved to a Case position, that is the Spec DP. The
definite marker in Bangla that is the Classifier, is potential enough to
cause opacity to allow chain formation. Syntax cannot see through the system
hence semantics decides the binding of the possessive pronominal in Bangla. Reference: Bhattacharya Tanmoy, 1998. DP-Internal NP Movement. UCL
Working papers in Linguistics 10. Kidwai Ayesha, 2000. XP-Adjunction in Universal Grammar
Scrambling and Binding in Hindi-Urdu, Oxford University
Press, 90-96. Reuland, Eric. 2001. Primitives of Binding. Linguistic
Inquiry Vol. 32. Number 3. 439-92. Reuland Eric, forthcoming.
Anaphora and Language Design. MIT Press. A Corpus-Based-Study of
Relative Clauses in Hindi and Telugu Transfer Grammar Rules for Relative
Clauses
Y.
Viswanatha Naidu LTRC, IIIT-Hyderabad, Gachibowli, Hyderabad, A.P., India.
Pin: 500032 E. Mail: viswanath.iiit@gmail.com Machine translation has gained increasingly more interest
since it was developed, but it is still not perfect. This would be solved,
not everything, by having the transfer grammar an approach to translate the
structures of source language to target language. It is also one of the
structural grammars which are a central design in Machine Translation. There
are also other approaches like Direct Transfer, Interlingua etc. However, in
my study I have chosen the Transfer Grammar. Perhaps the aim of this paper is
to study the nature of relative clauses in Hindi & Telugu and to develop
the transfer grammar after analyzing the relative clauses.� I divided the paper into two sections 1 for
the analysis of relative clauses in both languages and the other for the
transfer grammar for the relative clauses. In this paper I wish to focus my attention so much on
corpus based study and analysis of relative clauses�� in both i.e. Hindi and Telugu languages
and also to see which NP can be relativized in Telugu in terms of the noun
phrase accessibility proposed by Keenan and Comrie (1977). The accessibility
hierarchy (AH) is : Subject-->Direct Object-->Indirect Object-->Oblique-->Genitive-->Object
comparison--> where� '>' means
more accessible than.� And try to make
a set of Transfer Grammar rules� that
required for mapping the syntactic representations of a Source Language
(Hindi relative clause) to Target Language (Telugu relative clause), as in
fact� we know that languages have� their own mechanism to encode the
information. Some languages encode it explicitly through linguistic elements
which other languages may not express it explicitly, in which case they will
have their own mechanism to encode the information dynamics. For example in
Hindi ĵIs ĉəməĉ se maine khaayaa,(the spoon with
which I have eaten) here ĉəməĉ cannot be relativized like
*khaayahua ĉəməĉ, but in Telugu it is possible like nenu
tinna
ĉamĉaa (The spoon which I used). When such an situation occurs how
do we arrive from source structure (Hindi) to Target structure (Telugu)?
There comes the concept of 'Transfer Grammar', for which certain heuristics
are required to map the linguistic or nonlinguistic elements. Despite all its analyses, Hindi has two types of relative
clauses which are Correlative and Participle relative clauses. Correlatives
are more common than Participle. Furthermore, Correlatives can be divided
into restrictive clause and non restrictive clause. Correlative clauses can
be identified as they have explicit markers on them like ĵo....vo, ĵiskaa...ve/vo/pronoun,
whereas Participle constructions have no explicit markers. In Hindi Subject,
Direct object, Non-direct object and Possessor can be relativized. When it comes to the Telugu relative clauses, it has three
types of relativization processes. They are as follows
1).Participle,2).Clausal,3).Peri-clausal, of the three types (1) & (2)
are major types whereas (3) is close to clausal but is of conversational
style. References: CIIL Corpora. Keenan E and Comrie, B. 1977. Noun Phrase Accessibility and Universal Grammar. Krishnamurthy B.H, 1985. A Grammar of Modern Telugu (co authored with
J.P.L.Gwynn). New Delhi: Oxford University Press. Rama Rao Krishnamurthy B.H. 1968b. A Basic
Course in Modern Telugu. Hyderabad: Department of Linguistics, Osmania
University (co authored with P.Sivananda Sarma). 2006. Reprinted by Telugu
Academy, Himayatnagar, Hyderabad. Narasimha Shastri, Telugu vyakaranam Rama Rao C. Telugu vaakyam Rama Rao C. Telugu lo velugulu. Rama Rao C. A brief sketch on Telugu Rebecca Root �a two-way approach to structural Transfer in MT' University
of Texas. Yamuna Kachru Aspects of Hindi Grammar. 1980. New Delhi: Manohar. Yamuna Kachru A Contemporary Grammar of Hindi. (in Hindi), 1980.
Macmillan Company of India. Phonological Skills of
Hearing Impaired Children Using Cochlear Implants or Hearing Aids: A
Comparative Study
Naresh
D. Ali Yavar Jung National Institute for the Hearing
Handicapped-SRC, Secunderabad E.� Mail: nareshd15@gmail.com INTRODUCTION The speech of hearing impaired children is usually delayed
and disordered and exhibits a broad range of deviant speech patterns. Tobey (1993)
reported reduced phonetic repertories containing multiple errors and
substitutions in profoundly deaf children. Phonological processes are commonly used to describe
speech sound errors produced by young children (Lews et al., 2004; Morris
& Ozanne, 2003; Roberts et al., 2005). The articulatory error patterns
seen in hearing impaired children comprises of both developmental (e.g.,
cluster reduction, final consonant deletion, epenthesis, stopping,
assimilation etc) and non-developmental/ idiosyncratic (e.g., initial
consonant deletion, backing, denasalization etc) phonological processes. Phonological process label offer the potential advantage
of allowing the clinician to determine whether the errors are systematic in
their distribution or not (Cregnead, Newman, & Secord, 1989; Gordan-
Brannan & Weiss, 2007). By allowing clinicians to determine whether
errors cluster in particular ways therapy may then be focused on multiple
errors simultaneously, potentially making intervention more efficient. Conventional hearing aids enable
most deaf children to hear and gain access to spoken language by
amplification. Research indicates that cochlear implantation shows greater
speech production benefit for profoundly deafened children than do
conventional hearing aids. Increased sound repertoire and improvement in the
accuracy of articulation for profound hearing impaired children using
cochlear implant (Tobey and Hasenstab, 1991). Buhler, DeThomasis, Chute and
DeCora (2007) used the Goldman-Fristoe Test of Articulation-2 (Goldman &
Fristoe, 2000) on cochlear implant children and revealed the presence of five
patterns (final consonant deletion, stopping, cluster reduction, liquid
simplification and velar fronting) in them. However in Indian context, there
is a dearth of research in the area of acquisition of phonological skills in
children with cochlear implant and how do they differ in their phonological
skills of children using hearing aids. So the present study focuses on
examining the differential effect of amplification device (cochlear implant
vs. hearing aids), if any, on the phonological skills of Telugu speaking
profound hearing impaired children. AIM OF
THE STUDY The present study aimed at comparing the phonological
skills of Telugu speaking hearing impaired children using cochlear implant
and hearing aids. METHOD a)
Participants: 6
Telugu speaking children with congenital, bilateral severe to profound
hearing loss were recruited for the current study. Three of the participants
had multi channel cochlear implants (Nucleus 24) and three participants had
digital behind the ear hearing aids. Subject
selection criteria: �
Age
range: 7 to 9 years. �
Fitted
with a cochlear implant or hearing aid before the age of 4 years. This criterion increased the likelihood that the children
were using speech for communication, rather than babbling or non-speech
gestures. b)
Test material: Words
from Telugu articulation test in picture form served as the test stimuli. The
words included in the test comprised of all the consonants and vowels of
Telugu language in initial, middle and final positions. c)
Presentation of the stimuli: All the picture cards were presented one after the other
to the subjects in an individual set-up in a quiet environment. d)
Task: The
participants were asked to look carefully at the pictures and were asked to
name them in Telugu. e) Recording: The responses were audio recorded using Wavesurfer 6.0
software. f) Data
analysis: The responses on the articulation
test of both the groups was phonetically transcribed and phonologically
analyzed. Two phonological measures were used for the analysis: �
Percent
of Consonants Correct (PCC) - It is calculated by dividing the number of correct
consonants by the total number of consonant targets multiplied by 100. �
Phonological process analysis- The responses of all the
subjects were analyzed for the presence of phonological processes, if any.
The phonological processes used were sub-grouped into normal/developmental
and non-developmental/idiosyncratic processes. The percentage occurrence of
each process was calculated separately for each subject. g)
Statistical analysis: Appropriate statistical analysis
was done to compare the two groups (CI and HA group) on PCC and the
percentage use of different phonological processes. RESULTS The findings of the present study
revealed higher PCC in children with cochlear implant. Qualitative analysis
of the data revealed differences in the phonological processes used by the
two groups. The present study is a support to the existing corroborative
evidences of the presence of better phonological skills in cochlear implant
users than children using hearing aids with a similar degree of hearing loss. REFERENCES Goldman, R., & Fristoe, M.
(2000). Goldman-Fristoe Test of
Articulation-2. Circle Pines, MN: American Guidance Service. Buhler, H.C., DeThomasis, B.,
Chute, P., & DeCora, A. (2007). An analysis of phonological process use
in young children with cochlear implants. The
Volta Review, 107 (1), 55-74. Tobey, E. A., & Hasenstab,S. (1991).
Effects of a Nucleus multichannel cochlear implant upon speech production in
children. Ear and Hearing, 12
(Suppl), 48S-54S. Tobey, E. (1993). Speech production. In R. Tyler (Ed.),
Cochlear implants: Audiological
foundations (pp. 257-316). San Diego, CA: Singular Publishing Group. (Cregnead, N. A., Newman, P. W., & Secord,W.A. (1989).
Assessment and remediation of
articulatory and phonological disorders (2nd ed.). new York:
Macmillan Publishing Company. Gordan- Brannan, M.E., & Weiss, C,E. (2007). Clinical management of articulatory and
phonological disorders (3rd ed.). Philadelphia, PA: Lippincott
Williams & Wilkins.� Lews, B, A., Freebairn,L,A., Hansen, A., Taylor, G.
Iyengar, S., & Shriberg, L,D.(2004). Family pedigrees of children with
suspected childhood apraxia of speech. Journal
of communication disorders, 37(2), 157-175. Roberts, J., Long, S.H.,
Malkin,C., Barnes, E., Skinner, M., Hennon,E.A., & Anderson, K. (2005). A
comparison of phonological skills of boys with fragile X syndrome and Down
syndrome. Journal of Speech, Language
and Hearing Research, 48(5), 980-995. Ecolinguistics, Semantics and Pragmatics - Two Case
Studies: Hit Caurasi Pad and Norfolk Island, South Pacific
Joshua
Nash Discipline of Linguistics, University of Adelaide, SA
5005, Australia E.
Mail: joshua.nash@adelaide.edu.au Ecolinguistics
or the scientific study of language ecologies and the interaction between
language and the environment began as a subdiscipline of applied linguistics
in Western universities in the late 1970s. It is primarily concerned with:
Despite
several seminal works and although much has been written in various volumes
covering the theory and epistemology of ecolinguistics, the field still
awaits further theoretical expansion and synthesis within itself and together
with other fields of enquiry. The
multidisciplinary focus of ecolinguistics requires that ecolinguists take a
holistic approach embracing a multitude of perspectives both Eastern and
Western. It is proposed here that the discipline should strive ahead
utilising modern linguistic and environmental theories and technologies while
maintaining the validity of ancient basics and practical measures that are
the foundation of the area of enquiry. This
paper proposes a synthesis of ecolinguistics with:
It
employs two facets for analysis:
These
two case studies aim at founding some suggestions to advancing current
thought and theory in ecolinguistics through:
Reflexivity and Causation: A Study of the Vector ghe (TAKE) in Marathi
Renuka
Ozarkar Department of Linguistics, University of Mumbai E.
Mail: renuka_ozarkar@yahoo.com The compound verb construction (V-V
complex predicates) is one of the areal features of the South Asian
linguistic area. The Indo-Aryan languages in India have a comparably similar
set of verbs that occur as vectors or light verbs and form compound verb
constructions in these languages. These verbs are typically GIVE, TAKE, COME,
GO, PUT, DROP, SIT etc. These vector verbs show similar semantics in
Indo-Aryan languages in India. They typically contribute some aspectual
information such as telicity / perfectivity or inception (Butt 1995, Ramchand
2008). They also add some semantic nuances to the compound verb construction
such as benefaction, inadvertency, direction of the action etc. These nuances
are also comparably similar in these languages (Kachru 1993). The vector TAKE
in these languages generally expresses a reflexive sense (Masica 1976, Wali
2006), i.e. the direction of the action denoted by the main verb is towards
the agent, or the result of the action is transferable to the agent (at least
metaphorically). In Marathi, this vector ghe (TAKE) also express a
certain kind of causative for a class of verbs. The causation in Marathi is
either lexical (which show vowel change or consonant change or both in the
non-causative base) or formed morphologically (by adding the causative
morpheme �aw to the verb root). The morphological causative formation is more
productive than the lexical causative: the lexical causatives are available
only for a restricted set of intransitive verbs. Another causative
construction is periphrastic in nature, which is formed by using the verb laaw
(ATTACH/ force). Most of the transitive verbs in Marathi do not allow
morphological causative, while the periphrastic construction is highly
preferred for these verbs (Shibatani & Pardeshi 2003). The vector ghe (TAKE)
in Marathi is also used to form causatives from some such verbs, however the
vector retains its reflexive semantics. That is, the causer is somehow
involved in the main action or is the beneficiary / recipient of the result
of the caused action. For example,
1. mii�
rameS-kaDuun�� aambe������ paaD-uun������� / paaD-aw-uun ����� I���
Ramesh-from����� mangoes� drop.trans-CP / drop.trans-caus-CP �� ghet-l-e �� TAKE-perf-3p.pl.musc �� I got the mangoes dropped by Ramesh. (i.e.
I caused Ramesh to take the � �mangoes down from the tree). ����� 2. panCam-ne������� he��
gaaNe�� giitaa-kaDuun�� gaaw-uun ��� Pancham-ERG� this song����� Gita-from����� sing-CP ��� ghet-l-e ��� TAKE-perf-3p.sing.neut ��� Pancham got this song sung by Gita. In (1), the causer �I� is the
recipient or the beneficiary. In (2), the causer is closely involved in the
action of singing: he instructed or closely monitored the act of singing. He
is also the beneficiary of the act of singing. When the reflexive sense is
not possible, the causative cannot be formed by the vector ghe.
3. *mii��
rameS-kaDuun�� dZew-uun�� ghet-l-e ������� I����
Ramesh-from���� eat-CP������� TAKE-perf-3p.sing.neut ���� I caused Ramesh to have meal. The causer �I� cannot be the beneficiary
of the act of having the meal by Ramesh. The reflexivity and the causative
sense of the vector ghe appear to be closely linked. The causative
vector ghe also increases the valency of the compound verb
construction as is expected in a causative construction. In Marathi, ghe is
the only vector forming a typical �V-uun V� type of compound verb that
changes the valency of the main verb. The aspectual information by this
vector does not seem prominent as compared to the reflexive and causative
construction. This semantics of this vector needs to be formalized. Also its
selectional properties need a closer look. This paper will attempt to
describe and explain the behaviour of the vector ghe in Marathi. Analysis and Mathematical Model Generation for Letter
Frequencies in Text and in Word�s Initials for Hindi Language and Measurement
of Entropies of Most Frequent Consonants
Hemlata
Pande Deptt. of Mathematics, K. U. S. S. J. Campus, Almora,
Uttarakhand (INDIA) E. Mail: pande_hemlata1011@yahoo.com ����������� Frequencies of occurrence of
letters in natural language texts are not arbitrarily organized but follow
some particular rules, therefore on the basis of letter frequencies we are able to
explain some characteristic features of human language. The present work gives an
analysis of frequencies of letters of Hindi language alphabet on the basis of
their occurrence in a text and also for their occurrence as word�s initials.
We have applied Zipf�s law, which states that the frequency of the r-th most frequent
word type is proportional to 1/r, to the letters instead of words for
obtaining Zipf�s order and rank/frequency profiles of letters for their instances in text and
in beginning of words. Different distribution models have been tested for the
letter frequencies and finally appropriate parametric models have been given
for rank frequency distribution of letters in a corpus and for rank frequency
distribution of first letter of words in a text. Validations of the models
have been done by comparison of observed frequencies and theoretical
frequencies for various texts obtained from different sources, and the
variations in the values of parameters have been studied. And also for the
most frequent consonants a comparison has been done for their entropies in
text for the matras (dependent vowels) following the consonant. references: Eftekhari,
A., (2006). Fractal Geometry of Texts, An initial Application to the works of
Shakespeare, Journal of Quantitative Linguistics volume13, Numbers 2-3,
pp.177-193. Grzybek, P. and Kelih, E. (2005). Towards a general model of grapheme
frequencies in Slavic languages. In: Garab�k, R. (ed.), Computer Treatment of
Slavic and East European Languages: 73-87. Bratislava: Veda. Grzybek, P.,(2007). On the systematic and system based study of
grapheme frequencies: a re-analysis of German letter frequencies.
Glottometrics 15, 82-91. Manning,
C. D. and Schutze, H., (1999). Foundations of Statistical Natural Language
Processing, MIT Press. Naranan,
S. and Balasubrahmanyan, V. K., (1998). Models of Power Law Relations in
Linguistics and Information Science, Journal of Quantitative Linguistics, 5,
35-61. Sanderson, R. (2007). COMP527: Data Mining. Available at: www.csc.liv.ac.uk/~azaroth/courses/current/comp527/lectures/comp527-28.pdf ����������� Tambovtsev,Y.
and Martindale, C., (2007). Phoneme frequencies follow a Yule Distribution,
SKASE Journal of Theoretical Linguistics, vol. 4, no.2. Cross Language Variants in
Linguistic Deficits in Dementia of Alzheimer�s Type (DAT) Individuals
Sunil
Kumar Ravi All India Institute of Speech and Hearing, Manasagangotri,
Mysore � 06 E. Mail: rsunilkumar86@gmail.com Introduction: Dementia is a common clinical syndrome characterized by a
decline in the cognitive function and memory from previously attained
intellectual levels, which is sustained over a period of months or years. DAT
(Dementia of Alzheimer�s Type) is one of the common types of dementia seen in
dementia patients. Individuals with DAT will have little or no peripheral
weakness or incoordination and have no obvious motor speech deficits: control
of phonation, articulation, and resonance remains intact until the later
stages. The communication problems of this population are largely confined to
the two aspects of language: lexicon (word knowledge) and pragmatics. As
might be expected with a degenerative process, the deficits change from time
to time, and each phase of the disease is characterized by a distinct profile
of language deficits. The most frequently cited
communication problems in the literature include difficulty with verbal
memory, word finding (i.e., anomia), disruptive vocalizations, and
understanding of spoken language (i.e., auditory comprehension deficits). � Several research studies show that individuals with DAT
will exhibit obvious deficits in language. However, there are very less
number of studies focused on cross language deficits exhibited by these
individuals. Especially, there are very limited studies on this aspect in
Indian context. Aim: The aim of the present study was to study the cross
language variations in language deficits in DAT individuals in English and
Kannada. Method: 20 individuals with DAT in the age range of 45 to 65 years
were taken as subjects for this study. All the subjects were assessed on
Dementia Assessment Battery (DAB) in English and Kannada. DAB consists of
four domains, memory, linguistic comprehension, linguistic expression and
visuospatial construction with each domain consisting of several subtests. 20
normal subjects were also taken as controls for this study. Results: Performance of individuals
with DAT in Kannada and English were compared to study the cross language
variations in these subjects. And also the results of individuals with DAT
were compared with controls. Individuals with DAT showed poor performance in
all the tasks of the test compared to control subjects. And across languages,
DAT individuals performed well in most frequently used language when compared
to other language. Significant difference was found in linguistic expression
and linguistic comprehension tasks between two languages compared to memory
and visuospatial tasks.� Discussion:
Results indicated significant
differences in performance of individuals with DAT between two languages. It
was found that the individuals with DAT showed better performance in the most
used language than the other language. Implications of the study and the
results will be discussed in terms of cross language variations that are seen
in these subjects and its implications in speech and language assessment and
intervention. Positional Faithfulness for Weak Positions
Paroma
Sanyal EFL University, Hyderabad E. Mail: sanyalparoma@gmail.com Cross-linguistic evidence shows that perceptually and
psycholinguistically weak positions such as final syllables, affixal
syllables, and syllable coda are the common target for segment neutralization
processes. Beckman (1998) shows that by ranking a positional faithfulness
constraint specified for strong position above the markedness constraint
which motivates the neutralization we can get the desired result. Although
strong positions are best known for their ability to resist neutralization
processes, there are also cross-linguistics cases where these positions are
singled out in order to meet certain phonotactic criteria described by(de
Lacy 2000, 2001; Parker 2001; Smith 2000, 2002). Zoll (1998) uses the term
positional �augmentation� to refer to such phenomena. They propose a family
of positional markedness constraints specified for the strong position. Positional constraints are thus commonly specified for
strong positions. This analysis is based on the assumption that languages
make a greater effort to preserve material that is auditorily salient (Jun
1995; Steriade 1995). Zoll (1998) on the other hand refers to �negative
positional markedness constraints� such as License (labial) which bans labial
consonants from weak positions. The question that arises here is that do we
need to specify positional constraints for weak positions at all.
Positionally motivated augmentation will only target strong positions. But
segmental augmentation may be motivated by other phonological and
morphological process in the language. In this paper I discuss two such cases. In the first case
I borrow Guugu Yimidhirr data from Kager (1996) and Zoll (1998). Here a particular
morphological suffix triggers vowel lengthening in the final root vowel.
However, the first two syllables of a prosodic word are the only positions
where a long vowel can be licensed in the language. In their analysis they
show how positional constraints specified for strong position are inadequate
to block segmental augmentation in weak positions. For such cases, they show
that positional markedness constraint specified for weak positions are
required. In the second case I present data from Bangla which
reflects yet another logical possibility. The process of vowel harmony tries
to maximally match features between any two adjacent vocalic segments in a
word. The factorial typology of this harmony constraint may include
strategies in which the sonority of a vowel in strong position is reduced or
the sonority of a vowel in weak position is increased. Further, both high and
low sonority vowels can occur in strong and weak positions. However, the
language blocks the process of harmony from increasing the sonority of a
vowel in weak position. I argue that blocking augmentation of a weak position
need not necessarily entail that the weak position is a target of absolute
neutralization. Such languages have positional identity specified for weak
position. Recapitulating the discussion that we have had on the
typology of positional constraints we find that they are of four types.
Select References: Beckman, Jill. 1998. Positional Faithfulness. PhD
dissertation, University of Massachusetts, Amherst. De Lacy, Paul. 2001. Markedness in prominent positions.
Proceedings of HUMIT 2000 [MITWPL 40, Available on Rutgers
Optimality Archive, roa.rutgers.edu #282] De Lacy, Paul. 2002. The Formal Expression of
Markedness. Doctoral Dissertation, University of Massachusetts. Jun, Jongho. 1995. Perceptual and Articulatory factors
in Place Assimilation: An Optimality Theoretic Approach. Los Angeles, UCLA. Ph.D. dissertation. Kager, Rene. 1996. On affix allomorphy and syllable
counting. Utrecht. OTS working paper. Lombardi, Linda. 1999. Positional faithfulness and voicing
assimilation in Optimality Theory. Natural language and
Linguistic Theory 17: 267-302. Parker, Steve. 2001. Non-optimal laryngeal onsets in
Chamicuro. Phonology 18:361�386. Prince, Alan, and Paul Smolensky. 1993/2004. Optimality
Theory: Constraint Interaction in Generative Grammar . Malden, MA: Blackwell. Smith, Jennifer. 2000. Prominence, augmentation, and
neutralization in phonology. Berkeley Linguistics Society 26, 247-257. Smith, Jennifer. 2001. Lexical category and phonological
contrast. In R. Kirchner, J. Pater, and W. Wikely, eds. (2001). PETL
6: Proceedings of the Workshop on the Lexicon in Phonetics and Phonology. Edmonton: University of Alberta, 61-72. Smith, Jennifer. 2002. Phonological augmentation in
prominent positions. Doctoral dissertation, University of
Massachusetts, Amherst. Smith, Jennifer. 2005. Phonological augmentation in
prominent positions. Outstanding Dissertations in Linguistics. New
York and London: Routledge. Steriade, Donca. 1993. Positional neutralization.
Talk presented at NELS 24, University of Massachusetts, Amherst. Steriade, Donca. 1995. Positional neutralization.
Ms. University of California, Los Angeles. Zoll, Cheryl. 1998. Positional asymmetries and
licensing. Ms. MIT. [Available on Rutgers Optimality Archive,
roa.rutgers.edu #282] Zoll, Cheryl. 2004. Positional asymmetries and licensing.
In John McCarthy (ed.), Optimality Theory in Phonology: A Reader. Oxford: Blackwell, 365-378. Main Verb and Light Verb in
Bangla: Only Apparent Synonymy?
Syed
Saurov EFL University, Hyderabad E. Mail: syedsaurov@gmail.com Abstract: The aim of this paper is to carry out a preliminary
theoretical and analytical investigation into the syntactic and semantic
distinctions between the main verb and the light verb constructions in
Bangla. For a native Bangla speaker, there will be no difference
between the meaning of sentence (1) and sentence (2) both of which mean �I
have sent the letter� if they are presented as isolated iterations. 1)��������� ami������� �������� cithi�� -ta��
������� pathi- e- chi I-NOM� ��������� letter� DET� ��� send-PRSNT-PERF I have sent the letter 2)��������� ami���������������� cithi�� -ta�
�������� �pathi-e�� diy- e- chi I-NOM� ��������� letter� DET� ��� send-CP��
give-PRSNT-PERF I have sent the letter But Sentences (3) and (4) below show a distinction between
the semantic licensing of the light verb and lexical verb in a bi-clausal
structure. The main clause means �I have sent the letter�, while the
subordinate clause means �when John came and gave the news�. 3) ������� John������������ jokhon�� eS-e�������
khobor -ta�����
di-lo, John-NOM� when����
come-CP� news��� DET�
���������� give-PAST When John came and gave the news, (totokkhone) ami���� ��� cithi�� -ta��
������� pathi- e�� diy- e-
chi (by then)������ I-NOM�
letter�� DET� �� send-CP� give-PRSNT-PERF I have sent the letter 4) ������� *John������������ � jokhon�� eS-e�������
������� khobor
-ta����� � di-lo, John-NOM� ��� when���� come-CP�
����� news��� DET�
� give-PAST When John came and gave the news, (totokkhone) ami���� ��� cithi�� -ta��
������� pathi- e -chi (by then)������ I-NOM��
letter DET� ��� send- PRSNT-PERF I have sent the letter What is interesting is that to
express the relation between the meaning of the propositions in the main
clause and the subordinate clause, a native Bangla speaker has to use the
light verb �pathi-e�� diy-e-chi�. He cannot
say �pathi- e- chi�, even though he/she thinks that they are synonymous when
his/her judgement is asked about sentence (1) and sentence (2). So there has
to be some mechanism which is controlling this, that is allowing only one of
the two apparently similar forms. This means there has to be some difference,
syntactically and semantically, between these forms. Focus may play an
important role here, and the light verbs can contribute to the difference of
the sentences. In this paper, I will try to give a possible explanation for
this phenomenon in Bangla. Role of Working Memory in
Typically Developing Children�s Complex Sentence Comprehension
Shwetha
M.P, Deepthi M., Trupthi T., Nikhil Mathur & Deepa M.S. J.S.S. Institute of Speech and Hearing, Ooty Road, Mysore E.
Mail: shwth.jain@gmail.com Introduction: Working memory refers to the ability to store information while at
the same time engage in some kind of cognitively demanding activity such as
verbal reasoning or comprehension. These include a phonological short-term memory (PSTM) storage buffer
and a visuo-spatial short-term memory buffer, an attentional resource control
function, and processing speed. The ability to repeat nonwords is considered a sensitive index of
PSTM capacity because successful repetition requires children to invoke a
variety of phonological and memory-related processes independent of lexical
knowledge. Studies have, examined the relation between attentional resource
control/allocation and sentence comprehension in school age children where children
completed a concurrent verbal processing-storage task (i.e., listening span
task) and a sentence comprehension task that has been used in earlier
studies. Aim: To investigate the influence of
mechanisms of working memory that is phonological short-term memory (PSTM
capacity), attentional resource control/allocation (concurrent processing
storage score) on children�s complex (and simple) sentence comprehension. Method: Forty children
were equally divided into group I (7-9yrs) and group II (10-12 yrs) who completed a
nonword repetition task (indexing PSTM) and concurrent verbal
processing-storage task (indexing resource control/allocation). Result and
discussion: Statistical analysis was done on data obtained and results revealed
that (1) children were significantly more accurate in repeating short
nonwords (e.g., 2syllable items) than longer nonwords (e.g., 3-, 4- and
5-syllable items).� reflecting the
capacity-limited nature of the PSTM buffer (2)The memory variables didn�t
correlate with simple sentence comprehension, (3) resource control/allocation
correlated significantly with complex sentence comprehension, even after
co-varying for age. Conclusion: In concurrent
processing-storage task children comprehended significantly more simple sentences than complex
sentences along with production of nonwords. In sentence comprehension task
group II performed better than the group I for complex sentence
comprehension. In phonological short term memory the females in group II
performed better whereas in attentional resource control and allocation males
of group II performed better. It appears that controlled/flexible use of
attention plays a major role in complex sentence comprehension. REFERENCES: Adams, A., Bourke, L.,
&Willis, C. (1999).Working memory and spoken language comprehension in
youngchildren. International Journal of Psychology, 34, 364�373. Baddeley, A. (2003).Working
memory and language: An overview. Journal of Communication Disorders,
36,189�208. Barrouillet, P., & Camos,
V. (2001). Developmental increase in working memory span: Resource sharing or
temporal decay? Journal of Memory and Language, 45, 1�20. Daneman, M., & Carpenter,
P. (1983). Individual differences in integrating information between and
withinsentences. Journal of Experimental Psychology: Learning, Memory, and
Cognition, 9, 561�584. DeVilliers, J., &
DeVilliers, P. (1973). Development of the use of word order in comprehension.
Journal of Psycholinguistic Research, 2, 331�342. Dollaghan, C., & Campbell,
T. (1998). Nonword repetition and child language impairment. Journal of
Speech, Language, and Hearing Research, 41, 1136�1146. EllisWeismer, S., &
Thordardottir, E. (2002). Cognition and language. In P. Accardo, B. Rogers,
& A. Capute (Eds.), Disorders of language development. (pp. 21�37).
Timonium, MD: York Press, Inc. Gathercole, S., Pickering, S.,
Ambridge, B., & Wearing, H. (2004). The structure of working memory from
4 to 15 years of age. Developmental Psychology, 40, 177�190. Just, M., & Carpenter, P.
(1992). A capacity theory of comprehension: Individual differences in working
memory. Psychological Review, 99, 122�149. Montgomery, J. (2000a).
Relation of working memory to off-line and real-time sentence processing in
children with specific language impairment. Applied Psycholinguistics, 21,
117�148. Montgomery J, Magimairaj
BM,O�MalleyMH.(2008). Role of Working Memory in
Typically Developing Children's Complex Sentence Comprehension.journal of
psycholinguist research. Towse, J., Hitch, G., &
Hutton, U. (1998). A reevaluation of working memory capacity in children.
Journal of Memory and Language, 39, 195�217. Vallar,
G., & Baddeley, A. (1984). Phonological short-term store, phonological
processing and sentence comprehension:A neuropsychological case study.
Cognitive Neuropsychology, 1, 121�141. Beyond Honorificity: Analysis of Hindi jii
Gayetri
Thakur Deptt. of Linguistics, BHU, Varanasi E.
Mail: gayetrithakur@gmail.com The present work is about the distribution of a Hindi
particle jii traditionally categorized as an honorificity marker or
more recently suggested as a nominal classifier (Ghosh 2006). The primary aim
of the paper is to provide different pragmatic usages of this particle along
with its mapping in English. The data reveal that jii is used for
providing different kinds of speech-act information like seeking permission
(ex 1), requesting (ex. 2), questioning and answering to a question. It can
also be used for expressing the mood and the attitude of the speaker towards
addressee (ex 3). In a conversation (especially telephonic)(ex 4), it is used
as a filler by one participant to be with the other participant.������ 1.
jii
hameN bahar jaanaa thaa. PerP� we-dat out�
to go be-pt �Actually, we wanted to go out.� 2.
jii, aap
bhii kuch lijiye. ReqP you also something
take-hon-2p �Please take something.� 3.
kyuN jii
kyaa ho rahaa hai aajkal? �AttP���
what be aux-prog-3psg nowadays �So, what�s happening nowadays? ����� 4. Sab Khairiyat HeiN ��������� Everything right be-prt-2p ���������� Is everything all right? ���������� Jii� ��������� Yes ���������� Khana kha lena ��������� Food eat take-fut-2p ��������� Take your food ��������� Jii�. ��������� ok After identifying and characterizing the uses of jii, an
attempt has been made in the paper to provide the mapping rules for them to
disambiguate each one from others. For instance, in example (3), when the
particle is used for expressing speaker�s informal attitude to the addressee,
jii is always preceded by kyuN, which can be used as a cue in
the mapping rule. � By analyzing the polysemous nature of this particle, the
present work not only contributes to lexical semantics and pragmatics but
also adds relevant theoretical input to Hindi NLP especially in the areas of Word
Sense Disambiguation for Hindi and Hindi-English Machine Translation.� References: Ghosh Sanjukta. 2006. �Honorificity-marking Words of
Bangla and Hindi: Classifiers or not?� Bhashacintan, Vol 1, the
research journal of Department of Linguistics, Banaras Hindu
University Guru Kamta Prasad.1925.Hindi
Vyakran Nagari Pracharini Sabha Kashi. Fastmapping Skills in the
Developing Lexicon in Kannada Speaking Children
Trupthi
T., Deepthi M., Shwetha M.P., & Deepa M.S. & Nikhil Mathur J.S.S. Institute of Speech and Hearing, Ooty Road, Mysore E.
Mail: rao.trupthi@gmail.com Introduction: �An average toddler typically acquires a
lexicon of more than 500 words before the age of 3 yrs. One of the phases of
word learning is fast mapping. The incidental learning of new
vocabulary in the context of one to a few encounters is known as fast mapping
or quick incidental learning. Numerous studies have examined the fast mapping
phenomenon in preschoolers in the past decade. Researchers have found that
children are capable of mapping various aspects of a novel word. It includes
its referent, color, texture, function, semantic category, location and
action performed on referent as well as its phonological and syntactic
characteristics. These all reflect that children do comprehend the word after
the initial mapping stage, rather than just recognize the word. Purpose: This study aimed at investigating the underlying nature
of fast mapping by exploring children�s emerging ability to access
information in lexical memory. Method: Twenty children between the age range of 2 to 3 and 3 to
4 years, divided into two groups were taught 10 unfamiliar objects over the
sessions. Learning of new words by fast mapping and retrieval ability were
examined. Results: In the fast mapping phase of word learning process the
mean number of trials required for the children to fast map the target words
were less over the sessions. In the retention trial the mean percentage of
words recalled increased over the sessions and older group performed better than
the younger ones. Conclusion: The results indicated that the children in higher group
could fast map and recall more number of words than the lower group. In our
study children were provided with limited information about the nature and
the function of target words, yet they were united by all contexts in which
the words were acquired. REFERENCES: Bates, E., & Goodman, J. C.(1997). On the
inseparability of grammar and the lexicon: Evidence from acquisition, aphasia
and real-time processing. Language and cognition processes, 12,
507-584. Carey, S., & Bartlett, E. (1978). Acquiring a single
new word. Papers and reports in child language development, 15, 17-29 Chapman, R.S., Kay-Raining Bird, E., & Schwartz,
S.E.(1990). Fast mapping of words in event contexts by children with Down
syndrome. Journal of speech and hearing disorders, 55, 761-77. Dale, P.S, & Fenson, L. (1996). Lexical development
norms for young children. Behavior
research methods, instruments and computers, 28, 125-127. Dollaghan, C. A. (1985). Child meets word: �Fast mapping�
in pre school children. Journal of
speech and hearing, 28, 449-454. Dollaghan, C. A (1987). Fast mapping in normal and
language impaired children. Journal of
speech and hearing disorders, 52, 218-222. Gershkoff-Stowe, L. (2007). Fast mapping skills in
developing lexicon. Journal of speech,
language and hearing research, 50, 682-697. Golinkoff, R.M., Mervis, C.B., & Hirsh-Pasek, K.
(1994). Early object labels: The case for a developmental lexical principles
framework. Journal of child language,
21, 125-155. Heibeck, T., & Markman, E. (1987). Word learning in
children: an examination of fast mapping. Child
development, 58, 1021-1034. McDuffie, A. S. Sindberg H.A. Hesketh, L., Chapman,
R.(2007). Use of speaker intent and grammatical cues in fast mapping by
adolescents with Down syndrome. Journal
of speech language and hearing research, 50, 1546-1561. Reznick, J.S., & Goldfield, B.
A. (1992). Rapid change in lexical development in comprehension and
production. Developmental psychology,
28, 406-413. A Knowledge-Rich Computational Analysis of Marathi Derived
Forms
Ashwini
Vaidya LTRC, International Institute of Information Technology,
Gachibowli, Hyderabad 500032 E.
Mail: ashwini.vaidya@gmail.com A comprehensive analysis of morphological forms is
important for the computational processing of highly inflectional languages.
One of the productive morphological processes is derivation. Traditionally,
it implies the phenomenon where affixation changes the meaning as well as the
category of the stem. This paper describes a computational approach to
derived forms in Marathi. Dressler et al. (1987) have observed that certain
derivational affixes are more productive than others. As productive affixes
account for a greater number of forms, a corpus study was carried out to find
the most productive ones. This list was compiled along with rules for
morphophonemic changes using the open source morph analysis tool Lttoolbox. � As the process of derivation and inflection can operate
one after another, the use of nested paradigms was necessary to account for
such forms. The paper also describes the merging of the derivational
component with existing inflectional paradigms. This enables the recognition
of an inflected stem as well as a combination of derivation and inflection.
Finally, the results and evaluation of the work along with a discussion of
related issues is presented. References: Dressler, W.U., Mayerthaler, W., Panagl, Oswald and
Wurzel,W.U. (1987). Leitmotifs in
Natural Morphology. Amsterdam: J. Benjamins Lttoolbox: http://wiki.apertium.org/wiki/Lttoolbox Communication through Secret Language: A Case Study Based
on Parayas� Secret Language
Dileep
Vamanan Deptt. of Linguistics, University of Kerala, Kerala E.
Mail: dileep_knr@yahoo.co.in Language is the medium or tool for communication but
Secret Language also comes under this definition. A secret language is used
by a special group to preserve it identity and exclude outsiders. The terms refer
rather to the social function of a speech form than to any property of its
structure. Parayas is one among the community of scheduled cast in
Kerala. In the former time Parayas were slaves. Now Parayas are also
motivated to attain equality with other casts. They are using secret language
for their own special purposes. Parayas keep this language as a variety their
own and never allow others to learn or to use. They hardly reveal the
structure of the code nor give the details about the vocabulary or the secret
behind the use and development of variety. The claim that this secret code
was a long history and they are using this form for a long time. The basic
structure of the language is that of Malayalam. The phonology, morphology and
the syntactic structure of the language variety are almost same as that of
the language of the state. The most important feature of the language is its
vocabulary and it has no script. These have only oral form. The name of the
language is different in different region and its has some slight variation.
But that are intelligible to them. This language is in the way of death. The
youngsters in Paraya community are not initiated to study or used this
language. The aim of the paper is to investigate dialect variation of this language
and comparative study of Malayalam language Eg,������ kumita � house ����������� koonta
� house The people who are residing in Kollam (southern district
in Kerala) are using the term to refer to house is �kumita� but the people
who one in Kasaragod (Northernmost district in Kerala) used the term �koonta�
but this dialect variation does not affect their understanding become it is
intelligible to all at them. The methodology is used for this
study is field study method for the progress of the work direct contact with
the speakers will be done. Skeuomorphism
in Pānini
Dharurkar
Chinmay Vijay Deptt. of Humanities and Social Sciences, IIT Bombay,
Powai, Mumbai 400076 E. Mail: chinmayvijay@gmail.com Skeuomorphism is a term in the discipline of Design where it
refers to a design-feature functionally void but appears in a design, simply
because the users are used to the specific feature. A common example quoted
for a skeuomorph is that of the click sound that is featured in the
modern-tech digital cameras. Here, the click sound is not an outcome of the
very design of the modern-digital-technology-based digicams, as it used to be
of the old analogue cameras. So, it has no functional significance. It is
infact put into the cameras by an additional chip, which controls the
click-sound. So, the click sound in modern digicams is a skeuomorph of the
old functionally significant click sound. Similarly, in any discourse or discipline, old terms keep
gaining new, richer or deviated senses in the course of time. These terms are
not born anew, most of them are potential candidates to be skeuomorphs of the
older ones. By putting it in terms of skeuomorphism, we are not being
fashionable nor are we trying to be prolix by re-instating the already known
facts about the semiotics of nomenclature of terminology. We are interested 1. In looking critically at the development of the
nomenclature and terminology in any knowledge-system in general and Pāṇini in
particular. 2. In understanding how tradition accommodates and captures
this terminology. What meta-terminology it uses to formally put or understand
the nomenclature of the posterior. 3. In interrogating the very meta-terminology used within the
tradition to talk about the nature of the terms and terminology. To instantiate some of the skeuomorphs in Pāṇini:
sarvanāma, vibhakti, etc. Here, sarvanāma though a non-artificial
term, is not used in the normal sense of the word, though it may be distantly
related. It has qualified to be a skeuomorph because it has ceased to perform
the function to convey the notion of name of/for all and means only
what has been defined by Panini in P. 1.1.27 sarvādīni sarvanāmāni. |